- ↔
- →
to read (pdf)
- Letting AI Actively Manage Its Own Context | 明天的乌云
- Garden Offices for Sale UK - Portable Space
- Cord: Coordinating Trees of AI Agents | June Kim
- Style tips for less experienced developers coding with AI · honnibal.dev
- Haskell for all: Beyond agentic coding
- February 27, 2026
-
🔗 @HexRaysSA@infosec.exchange ❤️ LAST CHANCE for savings you'll love... mastodon
❤️ LAST CHANCE for savings you'll love...
IDA Pro’s 40% OFF* this Valentine's season.Use code LOVE40 by February 28 to get your license to the industry's best, for 40% less: http://hex-rays.com/license-love
*Terms apply.
-
🔗 sacha chua :: living an awesome life Using speech recognition for on-the-fly translations in Emacs and faking in-buffer completion for the results rss
When I'm writing a journal entry in French, I sometimes want to translate a phrase that I can't look up word by word using a dictionary. Instead of switching to a browser, I can use an Emacs function to prompt me for text and either insert or display the translation. The plz library makes HTTP requests slightly neater.
(defun my-french-en-to-fr (text &optional display-only) (interactive (list (read-string "Text: ") current-prefix-arg)) (let* ((url "https://translation.googleapis.com/language/translate/v2") (params `(("key" . ,(getenv "GOOGLE_API_KEY")) ("q" . ,text) ("source" . "en") ("target" . "fr") ("format" . "text"))) (query-string (mapconcat (lambda (pair) (format "%s=%s" (url-hexify-string (car pair)) (url-hexify-string (cdr pair)))) params "&")) (full-url (concat url "?" query-string))) (let* ((response (plz 'get full-url :as #'json-read)) (data (alist-get 'data response)) (translations (alist-get 'translations data)) (first-translation (car translations)) (translated-text (alist-get 'translatedText first-translation))) (when (called-interactively-p 'any) (if display-only (message "%s" translated-text) (insert translated-text))) translated-text)))I think it would be even nicer if I could use speech synthesis, so I can keep it a little more separate from my typing thoughts. I want to be able to say "Okay, translate …" or "Okay, … in French" to get a translation. I've been using my fork of natrys/whisper.el for speech recognition in English, and I like it a lot. By adding a function to
whisper-after-transcription-hook, I can modify the intermediate results before they're inserted into the buffer.(defun my-whisper-translate () (goto-char (point-min)) (let ((case-fold-search t)) (when (re-search-forward "okay[,\\.]? translate[,\\.]? \\(.+\\)\\|okay[,\\.]? \\(.+?\\) in French" nil t) (let* ((s (or (match-string 1) (match-string 2))) (translation (save-match-data (my-french-en-to-fr s)))) (replace-match (propertize translation 'type-hint translation 'help-echo s)))))) (with-eval-after-load 'whisper (add-hook 'whisper-after-transcription-hook 'my-whisper-translate 70))But that's too easy. I want to actually type things myself so that I get more practice. Something like an autocomplete suggestion would be handy as a way of showing me a hint at the cursor. The usual completion-at-point functions are too eager to insert things if there's only one candidate, so we'll just fake it with an overlay. This code works only with my whisper.el fork because it supports using a list of functions for
whisper-insert-text-at-point.(defun my-whisper-maybe-type-with-hints (text) "Add this function to `whisper-insert-text-at-point'." (let ((hint (and text (org-find-text-property-in-string 'type-hint text)))) (if hint (progn (my-type-with-hint hint) nil) text))) (defvar-local my-practice-overlay nil) (defvar-local my-practice-target nil) (defvar-local my-practice-start nil) (defun my-practice-cleanup () "Remove the overlay and stop monitoring." (when (overlayp my-practice-overlay) (delete-overlay my-practice-overlay)) (setq my-practice-overlay nil my-practice-target nil my-practice-start nil) (remove-hook 'post-command-hook #'my-practice-monitor t)) (defun my-practice-monitor () "Updates hint or cancels." (let* ((pos (point)) (input (buffer-substring-no-properties my-practice-start pos)) (input-len (length input)) (target-len (length my-practice-target))) (cond ((or (< pos my-practice-start) (> pos (+ my-practice-start target-len)) (string-match "[\n\t]" input) (string= input my-practice-target)) (my-practice-cleanup)) ((string-prefix-p (downcase input) (downcase my-practice-target)) (let ((remaining (substring my-practice-target input-len))) (move-overlay my-practice-overlay pos pos) (overlay-put my-practice-overlay 'after-string (propertize remaining 'face 'shadow)))) (t ; typo (move-overlay my-practice-overlay pos pos) (overlay-put my-practice-overlay 'after-string (propertize (substring my-practice-target input-len) 'face 'error)))))) (defun my-type-with-hint (string) "Show hints for STRING." (interactive "sString to practice: ") (my-practice-cleanup) (setq-local my-practice-target string) (setq-local my-practice-start (point)) (setq-local my-practice-overlay (make-overlay (point) (point) nil t t)) (overlay-put my-practice-overlay 'after-string (propertize string 'face 'shadow)) (add-hook 'post-command-hook #'my-practice-monitor nil t))Here's a demonstration of me saying "Okay, this is a test, in French.":
Screencast of using speech recognition to translate into French and provide a hint when typingSince we're faking in-buffer completion here, maybe we can still get away with considering this as an entry for Emacs Carnival February 2026: Completion ? =)
This is part of my Emacs configuration.You can e-mail me at sacha@sachachua.com.
-
🔗 r/Harrogate Looking for date location in Harrogate rss
Hi looking for date location like bar, im mid 20s dating slightly younger or my age.
belgrave in Leeds is my sort of place but gets busy and loud, went with flatmate and was so hard to hear them and talk even pretty early at 6pm, the walk there and from was actually better!!
So looking for somewhere quieter kinda cool vibe , not formal or
The ideal place would be something like Monty’s Bar that’s in Shoreditch which has sofas without it functioning as a main function room that belgrave does, more just like a edgy living room vibe and bar without the party
Thanks
submitted by /u/Apprehensive_Ring666
[link] [comments] -
🔗 r/wiesbaden Stau auflösen 2.0 rss
Die Partei hat immer recht.
submitted by /u/Affisaurus
[link] [comments] -
🔗 r/wiesbaden Morgen Plattenladen Pop-up in Mainz ✨🤝 rss
submitted by /u/EmploymentUnique2066
[link] [comments] -
🔗 remorses/critique critique@0.1.119 release
-
Real-time annotations on shared diff pages — collaborators can now leave comments and annotations directly on
critique.workdiff pages via the--webcommand -
Annotation widget auto-loads — the annotation UI loads automatically on web previews with real-time SSE updates as teammates add or resolve annotations
-
Fixed mobile web preview — mobile redirect now preserves scroll position and the annotation overlay renders correctly on small screens
-
-
🔗 blacktop/ida-mcp-rs v0.9.3 release
What's Changed
New Contributors
Full Changelog :
v0.9.2...v0.9.3What's Changed
- Update to IDA 9.3 release by @blacktop in #5
- fix: three correctness bugs (callees dedup, entrypoints hang, xref_matrix array arg) by @cpkt9762 in #6
New Contributors
Full Changelog :
v0.9.2...v0.9.3 -
🔗 r/york Need food ideas?! rss
Hi, I’m wanting to take my partner for a meal in York and wanting some recommendations. Happy to eat most cuisines but there is a seafood/fish allergy. Thank you in advance. If the place has online menus even better.
submitted by /u/Mormagon108
[link] [comments] -
🔗 hyprwm/Hyprland v0.54.0 release
A big (large), actually huge update for y'all!!
Special thanks to our HIs (Human Intelligences) for powering Hyprland development.
New features:
- cmakelists: add fno-omit-frame-pointer for tracy builds
- desktop/window: add stable id and use it for foreign
- gestures: add cursor zoom (#13033)
- groupbar: added group:groupbar:text_padding (#12818)
- hyprctl: add error messages to hyprctl hyprpaper wallpaper (#13234)
- hyprctl: add overFullscreen field in hyprctl window debug (#13066)
- hyprpm: add full nix integration (#13189)
- keybinds: add inhibiting gestures under shortcut inhibitors (#12692)
- main: add watchdog-fd and safe-mode options to help message (#12922)
- opengl: add debug:gl_debugging (#13183)
- start: add --force-nixgl and check /run/opengl-driver (#13385)
- start: add parent-death handling for BSDs (#12863)
Fixes:
- algo/dwindle: fix focal point not being properly used in movedTarget (#13373)
- algo/master: fix master:orientation being a noop
- algo/master: fix orientation cycling (#13372)
- algo/scrolling: fix crashes on destroying ws
- core/compositor: immediately do readable if adding waiter fails for scheduling state
- compositor: fix calculating x11 work area (#13347)
- config/descriptions: fix use_cpu_buffer (#13285)
- core/xwaylandmgr: fix min/max clamp potentially crashing
- decorations/border: fix damage scheduling after #12665
- desktop/layerRuleApplicator: fix an epic c+p fail
- desktop/ls: fix invalid clamp
- desktop/popup: fix use after free in Popup (#13335)
- desktop/reserved: fix a possible reserved crash (#13207)
- desktop/ruleApplicator: fix typo in border color rule parsing (#12995)
- desktop/rules: fix border colors not resetting. (#13382)
- desktop/workspaceHistory: fix tracking for multiple monitors (#12979)
- desktopAnimationMgr: fix slide direction
- dynamicPermManager: fix c+p fail
- eventLoop: various eventloopmgr fixes (#13091)
- example: fixup config for togglesplit
- fifo: miscellaneous fifo fixes (#13136)
- fix: handle fullscreen windows on special workspaces (#12851)
- hyprctl: fix layerrules not being applied dynamically with hyprctl (#13080)
- hyprerror: add padding & adjust for scale when reserving area (#13158)
- hyprerror: fix horizontal overflow and damage box (#12719)
- hyprpm: fix build step execution
- hyprpm: fix clang-format
- input: fix edge grab resize logic for gaps_out > 0 (#13144)
- input: fix kinetic scroll (#13233)
- keybinds: fix unguarded member access in moveWindowOrGroup (#13337)
- mainLoopExecutor: fix incorrect pipe check
- monitor: fix DS deactivation (#13188)
- multigpu: fix multi gpu checking (#13277)
- nix: add hyprland-uwsm to passthru.providedSessions
- nix: fix evaluation warnings, the xorg package set has been deprecated (#13231)
- pluginsystem: fix crash when unloading plugin hyprctl commands (#12821)
- protocols/cm: Fix image description info events (#12781)
- protocols/contentType: fix missing destroy
- protocols/contentType: fix typo in already constructed check
- protocols/dmabuf: fix DMA-BUF checks and events (#12965)
- protocols/syncobj: fix DRM sync obj support logging (#12946)
- renderer/pass: fix surface opaque region bounds used in occluding (#13124)
- renderer: add surface shader variants with less branching and uniforms (#13030)
- renderer: optimise shader usage further, split shaders and add more caching (#12992)
- renderer: fix dgpu directscanout explicit sync (#13229)
- renderer: fix frame sync (#13061)
- renderer: fix mouse motion in VRR (#12665)
- renderer: fix non shader cm reset (#13027)
- renderer: fix screen export back to srgb (#13148)
- systemd/sdDaemon: fix incorrect strnlen
- target: fix geometry for x11 floats
- tester: fix sleeps waiting for too long (#12774)
- xwayland/xwm: fix _NET_WM_STATE_MAXIMIZED_VERT type (#13151)
- xwayland/xwm: fix window closing when props race
- xwayland: fix size mismatch for no scaling (#13263)
Other:
- Nix: apply glaze patch
- Nix: re-enable hyprpm
- Reapply "hyprpm: bump glaze version"
- Revert "hyprpm: bump glaze version"
- algo/scrolling: adjust focus callbacks to be more intuitive
- animation: reset tick state on session activation (#13024)
- animationMgr: avoid uaf in ::tick() if handleUpdate destroys AV
- anr: open anr dialog on parent's workspace (#12509)
- anr: remove window on closewindow (#13007)
- buffer: add move constructor and operator to CHLBufferReference (#13157)
- cm: block DS for scRGB in HDR mode (#13262)
- cmake: bump wayland-server version to 1.22.91 (#13242)
- cmake: use OpenGL::GLES3 when OpenGL::GL does not exist (#13260)
- cmakelists: don't require debug for tracy
- compositor: guard null view() in getWindowFromSurface (#13255)
- config: don't crash on permission with a config check
- config: return windowrulev2 layerrulev2 error messages (#12847)
- config: support no_vrr rule on vrr 1 (#13250)
- core: optimize some common branches
- decoration: take desiredExtents on all sides into account (#12935)
- dekstop/window: read static rules before guessing initial size if possible (#12783)
- desktop/LS: avoid creating an invalid LS if no monitor could be found (#12787)
- desktop/ls: clamp layer from protocol
- desktop/popup: avoid crash on null popup child in rechecking
- desktop/popup: only remove reserved for window popups
- desktop/reservedArea: clamp dynamic types to 0
- desktop/reservedArea: clamp to 0
- desktop/rules: use pid for exec rules (#13374)
- desktop/window: avoid uaf on instant removal of a window
- desktop/window: catch bad any cast tokens
- desktop/window: go back to the previously focused window in a group (#12763)
- desktop/window: remove old fn defs
- desktop/window: track explicit workspace assignments to prevent X11 configure overwrites (#12850)
- desktop/window: use workArea for idealBB (#12802)
- desktop/windowRule: allow expression in min_size/max_size (#12977)
- desktop/windowRule: use content rule as enum directly (#13275)
- desktop: restore invisible floating window alpha/opacity when focused over fullscreen (#12994)
- event: refactor HookSystem into a typed event bus (#13333)
- eventLoop: remove failed readable waiters
- framebuffer: revert viewport (#12842)
- gestures/fs: remove unneeded floating state switch (#13127)
- hyprctl: adjust json case
- hyprctl: bump hyprpaper protocol to rev 2 (#12838)
- hyprctl: remove trailing comma from json object (#13042)
- hyprerror: clear reserved area on destroy (#13046)
- hyprpm,Makefile: drop cmake ninja build
- hyprpm: bump glaze version
- hyprpm: drop meson dep
- hyprpm: exclude glaze from all targets during fetch
- hyprpm: use provided pkgconf env if available
- i18n: add Romanian translations (#13075)
- i18n: add Traditional Chinese (zh_TW) translations (#13210)
- i18n: add Vietnamese translation (#13163)
- i18n: add bengali translations (#13185)
- i18n: update russian translation (#13247)
- input/TI: avoid UAF in destroy
- input/ti: avoid sending events to inactive TIs
- input: guard null
view()when processing mouse down (#12772) - input: use fresh cursor pos when sending motion events (#13366)
- internal: removed Herobrine
- layershell: restore focus to layer shell surface after popup is destroyed (#13225)
- layout: rethonk layouts from the ground up (#12890)
- monitor: revert "remove disconnected monitor before unsafe state #12544" (#13154)
- nix: remove glaze patch
- opengl/fb: use GL_DEPTH24_STENCIL8 instead of GL_STENCIL_INDEX8 (#13067)
- opengl: allow texture filter to be changed (#13078)
- opengl: set EGL_CONTEXT_RELEASE_BEHAVIOR_KHR if supported (#13114)
- pointermgr: damage only the surface size (#13284)
- pointermgr: remove onRenderBufferDestroy (#13008)
- pointermgr: revert "damage only the surface size (#13284)"
- popup: check for expired weak ptr (#13352)
- popup: reposition with reserved taken into account
- proto/shm: update wl_shm to v2 (#13187)
- protocolMgr: remove IME / virtual input protocols from sandbox whitelist
- protocols/toplevelExport: Support transparency in toplevel export (#12824)
- protocols: implement image-capture-source-v1 and image-copy-capture-v1 (#11709)
- renderer/fb: dont forget to set m_drmFormat (#12833)
- renderer/gl: add internal gl formats and reduce internal driver format conversions (#12879)
- renderer/opengl: invalidate intermediate FBs post render, avoid stencil if possible (#12848)
- renderer: allow tearing with DS with invisible cursors (#13155)
- renderer: better sdr eotf settings (#12812)
- renderer: minor framebuffer and renderbuffer changes (#12831)
- renderer: shader code refactor (#12926)
- shm: ensure we use right gl unpack alignment (#12975)
- start: use nixGL if Hyprland is nix but not NixOS (#12845)
- systemd/sdDaemon: initialize sockaddr_un
- testers: add missing #include
(#12862) - tests: Test the
no_focus_on_activatewindow rule (#13015) - time: ensure type correctness and calculate nsec correctly (#13167)
- versionKeeper: ignore minor rev version
- view: send wl_surface.enter to subsurfaces of popups (#13353)
- wayland/output: return all bound wl_output instances in outputResourceFrom (#13315)
- welcome: skip in safe mode
- xwayland/xwm: get supported props on constructing surface (#13156)
- xwayland/xwm: handle INCR clipboard transfer chunks correctly (#13125)
- xwayland/xwm: prevent onWrite infinite loop and clean orphan transfers (#13122)
- xwayland: ensure NO_XWAYLAND builds (#13160)
- xwayland: normalize OR geometry to logical coords with force_zero_scaling (#13359)
- xwayland: validate size hints before floating (#13361)
Special thanks
As always, massive thanks to our wonderful donators and sponsors:
Sponsors
Diamond
37Signals
Gold
Framework
Donators
Top Supporters:
Seishin, Kay, johndoe42, d, vmfunc, Theory_Lukas, --, MasterHowToLearn, iain, ari-cake, TyrHeimdal, alexmanman5, MadCatX, Xoores, inittux111, RaymondLC92, Insprill, John Shelburne, Illyan, Jas Singh, Joshua Weaver, miget.com, Tonao Paneguini, Brandon Wang, Arkevius, Semtex, Snorezor, ExBhal, alukortti, lzieniew, taigrr, 3RM, DHH, Hunter Wesson, Sierra Layla Vithica, soy_3l.beantser, Anon2033, Tom94
New Monthly Supporters:
monkeypost, lorenzhawkes, Adam Saudagar, Donovan Young, SpoderMouse, prafesa, b3st1m0s, CaptainShwah, Mozart409, bernd, dingo, Marc Galbraith, Mongoss, .tweep, x-wilk, Yngviwarr, moonshiner113, Dani Moreira, Nathan LeSueur, Chimal, edgarsilva, NachoAz, mo, McRealz, wrkshpstudio, crutonjohn
One-time Donators:
macsek, kxwm, Bex Jonathan, Alex, Tomas Kirkegaard, Viacheslav Demushkin, Clive, phil, luxxa, peterjs, tetamusha, pallavk, michaelsx, LichHunter, fratervital, Marpin, SxK, mglvsky, Pembo, Priyav Shah, ChazBeaver, Kim, JonGoogle, matt p, tim, ybaroj, Mr. Monet Baches, NoX, knurreleif, bosnaufal, Alex Vera, fathulk, nh3, Peter, Charles Silva, Tyvren, BI0L0G0S, fonte-della- bonitate, Alex Paterson, Ar, sK0pe, criss, Dnehring, Justin, hylk, 邱國玉KoryChiu, KSzykula, Loutci, jgarzadi, vladzapp, TonyDuan, Brian Starke, Jacobrale, Arvet, Jim C, frank2108, Bat-fox, M.Bergsprekken, sh-r0, Emmerich, davzucky, 3speed, 7KiLL, nu11p7r, Douglas Thomas, Ross, Dave Dashefsky, gignom, Androlax, Dakota, soup, Mac, Quiaro, bittersweet, earthian, Benedict Sonntag, Plockn, Palmen, SD, CyanideData, Spencer Flagg, davide, ashirsc, ddubs, dahol, C. Willard A.K.A Skubaaa, ddollar, Kelvin, Gwynspring, Richard, Zoltán, FirstKix, Zeux, CodeTex, shoedler, brk, Ben Damman, Nils Melchert, Ekoban, D., istoleyurballs , gaKz, ComputerPone, Cell the Führer, defaltastra, Vex, Bulletcharm, cosmincartas, Eccomi, vsa, YvesCB, mmsaf, JonathanHart, Sean Hogge, leat bear, Arizon, JohannesChristel, Darmock, Olivier, Mehran, Anon, Trevvvvvvvvvvvvvvvvvvvv, C8H10N4O2, BeNe, Ko-fi Supporter :3, brad, rzsombor, Faustian, Jemmer, Antonio Sanguigni, woozee, Bluudek, chonaldo, LP, Spanching, Armin, BarbaPeru, Rockey, soba, FalconOne, eizengan, むらびと, zanneth, 0xk1f0, Luccz, Shailesh Kanojia, ForgeWork , Richard Nunez, keith@groupdigital.com, pinklizzy, win_cat_define, Bill, johhnry, Matysek, anonymus, github.com/wh1le, Iiro Ullin, Filinto Delgado, badoken, Simon Brundin, Ethan, Theo Puranen Åhfeldt, PoorProgrammer, lukas0008, Paweł S, Vandroiy, Mathias Brännström, Happyelkk, zerocool823, Bryan, ralph_wiggums, DNA, skatos24, Darogirn , Hidde, phlay, lindolo25, Siege, Gus, Max, John Chukwuma, Loopy, Ben, PJ, mick, herakles, mikeU-1F45F, Ammanas, SeanGriffin, Artsiom, Erick, Marko, Ricky, Vincent mouline
Full Changelog :
v0.53.0...v0.54.0 -
🔗 r/york A wander around the streets.. rss
 | submitted by /u/OpportunityNearby827
| submitted by /u/OpportunityNearby827
[link] [comments]
---|--- -
🔗 News Minimalist 🐢 Pakistan and Afghanistan at war + 10 more stories rss
In the last 3 days ChatGPT read 94301 top news stories. After removing previously covered events, there are 11 articles with a significance score over 5.5.

[6.2] Afghanistan and Pakistan engage in open war following cross-border attacks —abcnews.com(+215)
Pakistan’s defense minister declared an “open war” with Afghanistan on Friday following a significant escalation in cross-border military strikes, marking the most serious confrontation between the neighbors in years.
Following Afghan cross-border attacks Thursday, Pakistan launched retaliatory airstrikes on Kabul and Kandahar. Tensions have peaked over Pakistan’s claims that Afghanistan harbors TTP militants, an allegation Kabul denies while citing civilian casualties from recent Pakistani military operations along the porous frontier.
[6.3] Pentagon demands unrestricted military access to Anthropic's AI or risks contract loss —apnews.com(+100)
Defense Secretary Pete Hegseth gave Anthropic a Friday deadline to allow unrestricted military use of its AI or risk losing government contracts and facing Defense Production Act intervention.
Defense officials suggested invoking the Cold War-era Defense Production Act to bypass Anthropic's ethical restrictions. This unprecedented move aims to integrate Claude AI into military networks despite leadership concerns regarding autonomous weaponry, mass surveillance, and safety limits for artificial intelligence.
While the DPA historically boosts production during emergencies like pandemics, experts warn that using it to dictate service terms is legally questionable and could trigger significant litigation between Anthropic and the government.
[5.5] EU expands funding for abortion access within the bloc —apnews.com(+24)
The European Commission has authorized using the 147 billion euro European Social Funds Plus to support citizens traveling to access safe abortions from EU nations with restrictive health laws.
This decision follows the My Voice, My Choice campaign, which gathered over one million signatures via the European Citizens’ Initiative. While no new fund was created, the Commission confirmed that existing resources can defray costs for women seeking legal healthcare across borders.
Although abortion is legal in most of Europe, it remains highly restricted in countries like Poland and Malta. Proponents call the move a victory for social justice, while some critics oppose the intervention.
Highly covered news with significance over 5.5
[6.0] Chip giant Nvidia defies AI concerns with record $215bn revenue — bbc.com (+138)
[6.5] World-first stem cell therapy trial shows promise for treating spina bifida in the womb — nature.com (+6)
[5.9] France's National Assembly approves assisted dying bill — lalibre.be (French) (+7)
[5.9] Chinese scientists transform desert sand into fertile soil using microbes — en.tempo.co (+2)
[5.7] Novartis settles with Henrietta Lacks' estate over use of her cells — independent.co.uk (+10)
[5.6] Germany's ruling parties reverse heat pump mandate, allowing homeowner choice — nzz.ch (German) (+9)
[5.5] UK's first geothermal power plant generates electricity for 10,000 homes and produces lithium — bbc.com (+2)
[5.5] Chilean telescope captures detailed view of Milky Way's star-forming core — apnews.com (+33)
Thanks for reading!
— Vadim
You can customize this newsletter with premium.
-
🔗 r/wiesbaden essbare Blumen rss
Hat jemand eine Idee, wo ich in Wiesbaden essbare Blumen kaufen kann, um einen Kuchen zu dekorieren? :)
submitted by /u/Turbulent_Life_5826
[link] [comments] -
🔗 r/Yorkshire Jake Lambert will be headlining a comedy evening at The Glee Club Leeds on 10th June, in aid of Epilepsy Action! rss
 | submitted by /u/NationalDoodleDay
| submitted by /u/NationalDoodleDay
[link] [comments]
---|--- -
🔗 3Blue1Brown (YouTube) The most beautiful formula not enough people understand rss
On the volumes of higher-dimensional spheres Explore the 3b1b virtual career fair: See https://3b1b.co/talent Become a supporter for early views of new videos: https://3b1b.co/support An equally valuable form of support is to simply share the videos. Home page: https://www.3blue1brown.com
Thanks to UC Santa Cruz for letting me film there, and special thanks to Pedro Morales-Almazan for arranging everything.
My video on Numberphile with a fun application of this problem: https://youtu.be/6_yU9eJ0NxA
Timestamps: 0:00 - Introduction 1:01 - Random puzzle 6:16 - Outside the box 14:35 - Setting up the volume grid 21:14 - Why 4πr^2 25:21 - Archimedes in higher dimensions 36:17 - The general formula 40:40 - 1/2 factorial 44:58 - Why 5D spheres are the biggest 50:16 - Concentration at the surface 54:27 - A unit-free interpretation 57:50 - 3b1b Talent 59:13 - Explaining the intro animation
These animations are largely made using a custom Python library, manim. See the FAQ comments here: https://3b1b.co/faq#manim
Music by Vincent Rubinetti. https://vincerubinetti.bandcamp.com/album/the-music-of-3blue1brown https://open.spotify.com/album/1dVyjwS8FBqXhRunaG5W5u
3blue1brown is a channel about animating math, in all senses of the word animate. If you're reading the bottom of a video description, I'm guessing you're more interested than the average viewer in lessons here. It would mean a lot to me if you chose to stay up to date on new ones, either by subscribing here on YouTube or otherwise following on whichever platform below you check most regularly.
Mailing list: https://3blue1brown.substack.com Twitter: https://twitter.com/3blue1brown Bluesky: https://bsky.app/profile/3blue1brown.com Instagram: https://www.instagram.com/3blue1brown Reddit: https://www.reddit.com/r/3blue1brown Facebook: https://www.facebook.com/3blue1brown Patreon: https://patreon.com/3blue1brown Website: https://www.3blue1brown.com
-
🔗 r/LocalLLaMA PewDiePie fine-tuned Qwen2.5-Coder-32B to beat ChatGPT 4o on coding benchmarks. rss
 | submitted by /u/hedgehog0
| submitted by /u/hedgehog0
[link] [comments]
---|--- -
🔗 r/Harrogate New Royal Hunting Forest exhibition in Knaresborough rss
submitted by /u/No_Nose_3849
[link] [comments] -
🔗 r/Yorkshire Whitby against racism rss
 | submitted by /u/johnsmithoncemore
| submitted by /u/johnsmithoncemore
[link] [comments]
---|--- -
🔗 r/york Hidden gems to explore in York rss
 | Reddit tricked me into reading an AI-generated page about hidden gems in York. I'm pleased to report that everyone's favourite cafe has made the list! See the screenshot below. Reddit cites u/WhapXI's comment and u/WhatWeHavingForTea's comment as evidence. I would like to compliment the AI on its refined taste in cafes. https://preview.redd.it/v4yf71es11mg1.png?width=865&format=png&auto=webp&s=0df8d86bbac10bb61f12d53de2e64b9921681f8e See for yourself here: https://www.reddit.com/answers/7d474f44-7294-4c6f-ad77-e40716ed14f8/?q=Hidden+gems+to+explore+in+York&source=PDP&tl=en . submitted by /u/sbernard
| Reddit tricked me into reading an AI-generated page about hidden gems in York. I'm pleased to report that everyone's favourite cafe has made the list! See the screenshot below. Reddit cites u/WhapXI's comment and u/WhatWeHavingForTea's comment as evidence. I would like to compliment the AI on its refined taste in cafes. https://preview.redd.it/v4yf71es11mg1.png?width=865&format=png&auto=webp&s=0df8d86bbac10bb61f12d53de2e64b9921681f8e See for yourself here: https://www.reddit.com/answers/7d474f44-7294-4c6f-ad77-e40716ed14f8/?q=Hidden+gems+to+explore+in+York&source=PDP&tl=en . submitted by /u/sbernard
[link] [comments]
---|--- -
🔗 r/reverseengineering magisk-renef — Auto-run renef dynamic instrumentation server on Android via Magisk/KernelSU rss
submitted by /u/ResponsiblePlant8874
[link] [comments] -
🔗 r/york Some photos I took of your beautiful city last week! rss
 | Went to York on holiday last week to see prima facie and took some photos. I had the best time and everyone was super nice, definitely coming back sometime:) submitted by /u/Organic_Repair8717
| Went to York on holiday last week to see prima facie and took some photos. I had the best time and everyone was super nice, definitely coming back sometime:) submitted by /u/Organic_Repair8717
[link] [comments]
---|--- -
🔗 r/Leeds Bra fitting rss
I’ve been debating to get a proper bra fitting before I buy new but idk where is best in the Leeds city centre to get fitted like there’s few bra shops there pour moi , Ann summers and bravissimo all I know of unless there is more I wanted to know where is best to get decent fitted
submitted by /u/Trashbandit_seal
[link] [comments] -
🔗 r/Yorkshire Fishlake, St Cuthbert, South Yorkshire The 12thC south doorway, with four orders of sculpture, is one of Yorkshire’s finest examples of a Romanesque door. rss
 | @simonsmith submitted by /u/Mundane-Temporary426
| @simonsmith submitted by /u/Mundane-Temporary426
[link] [comments]
---|--- -
🔗 r/Leeds Mitski show rss
Hello all,
I've got the tickets for the mistki show happening in Leeds in May. I know it's still some time but i was wondering if anyone else has also got the tickets and looking to go together?
I dont live in Leeds anymore and none of my friends listen to Mistki so it would be nice to go with someone and enjoy the show together.
Thanks!
submitted by /u/benzene_burner33
[link] [comments] -
🔗 r/reverseengineering Building a map tool for Cataclismo rss
submitted by /u/Bobby_Bonsaimind
[link] [comments] -
🔗 Stavros' Stuff Latest Posts I made a voice note taker rss
It's small and tiny and so cuteHave you ever always wanted a very very small voice note recorder that would fit in your pocket? Something that would always work, and always be available to take a note at the touch of a button, with no fuss? Me neither.
Until, that is, I saw the Pebble Index 01, then I absolutely needed it right away and had to have it in my life immediately, but alas, it is not available, plus it’s disposable, and I don’t like creating e-waste. What was a poor maker like me supposed to do when struck down so cruelly by the vicissitudes of fate?
There was only one thing I could do:
I could build my own, shitty version of it for $8, and that’s exactly what I did.
The problem
Like everyone else, I have some sort of undiagnosed ADHD, which manifests itself as my brain itching for a specific task, and the itch becoming unbearable unless I scratch it. This usually results in me getting my
-
🔗 Baby Steps How Dada enables internal references rss
In my previous Dada blog post, I talked about how Dada enables composable sharing. Today I'm going to start diving into Dada's permission system; permissions are Dada's equivalent to Rust's borrow checker.
Goal: richer, place-based permissions
Dada aims to exceed Rust's capabilities by using place-based permissions. Dada lets you write functions and types that capture both a value and things borrowed from that value.
As a fun example, imagine you are writing some Rust code to process a comma- separated list, just looking for entries of length 5 or more:
let list: String = format!("...something big, with commas..."); let items: Vec<&str> = list .split(",") .map(|s| s.trim()) // strip whitespace .filter(|s| s.len() > 5) .collect();One of the cool things about Rust is how this code looks a lot like some high- level language like Python or JavaScript, but in those languages the
splitcall is going to be doing a lot of work, since it will have to allocate tons of small strings, copying out the data. But in Rust the&strvalues are just pointers into the original string and sosplitis very cheap. I love this.On the other hand, suppose you want to package up some of those values, along with the backing string, and send them to another thread to be processed. You might think you can just make a struct like so…
struct Message { list: String, items: Vec<&str>, // ---- // goal is to hold a reference // to strings from list }…and then create the list and items and store them into it:
let list: String = format!("...something big, with commas..."); let items: Vec<&str> = /* as before */; let message = Message { list, items }; // ---- // | // This *moves* `list` into the struct. // That in turn invalidates `items`, which // is borrowed from `list`, so there is no // way to construct `Message`.But as experienced Rustaceans know, this will not work. When you have borrowed data like an
&str, that data cannot be moved. If you want to handle a case like this, you need to convert from&strinto sending indices, owned strings, or some other solution. Argh!Dada's permissions use places , not lifetimes
Dada does things a bit differently. The first thing is that, when you create a reference, the resulting type names the place that the data was borrowed from , not the lifetime of the reference. So the type annotation for
itemswould sayref[list] String1 (at least, if you wanted to write out the full details rather than leaving it to the type inferencer):let list: given String = "...something big, with commas..." let items: given Vec[ref[list] String] = list .split(",") .map(_.trim()) // strip whitespace .filter(_.len() > 5) // ------- I *think* this is the syntax I want for closures? // I forget what I had in mind, it's not implemented. .collect()I've blogged before about how I would like to redefine lifetimes in Rust to be places as I feel that a type like
ref[list] Stringis much easier to teach and explain: instead of having to explain that a lifetime references some part of the code, or what have you, you can say that "this is aStringthat references the variablelist".But what's also cool is that named places open the door to more flexible borrows. In Dada, if you wanted to package up the list and the items, you could build a
Messagetype like so:class Message( list: String items: Vec[ref[self.list] String] // --------- // Borrowed from another field! ) // As before: let list: String = "...something big, with commas..." let items: Vec[ref[list] String] = list .split(",") .map(_.strip()) // strip whitespace .filter(_.len() > 5) .collect() // Create the message, this is the fun part! let message = Message(list.give, items.give)Note that last line -
Message(list.give, items.give). We can create a new class and movelistinto it along withitems, which borrows from list. Neat, right?OK, so let's back up and talk about how this all works.
References in Dada are the default
Let's start with syntax. Before we tackle the
Messageexample, I want to go back to theCharacterexample from previous posts, because it's a bit easier for explanatory purposes. Here is some Rust code that declares a structCharacter, creates an owned copy of it, and then gets a few references into it.struct Character { name: String, class: String, hp: u32, } let ch: Character = Character { name: format!("Ferris"), class: format!("Rustacean"), hp: 22 }; let p: &Character = &ch; let q: &String = &p.name;The Dada equivalent to this code is as follows:
class Character( name: String, klass: String, hp: u32, ) let ch: Character = Character("Tzara", "Dadaist", 22) let p: ref[ch] Character = ch let q: ref[p] String = p.nameThe first thing to note is that, in Dada, the default when you name a variable or a place is to create a reference. So
let p = chdoesn't movech, as it would in Rust, it creates a reference to theCharacterstored inch. You could also explicitly writelet p = ch.ref, but that is not preferred. Similarly,let q = p.namecreates a reference to the value in the fieldname. (If you wanted to move the character, you would writelet ch2 = ch.give, notlet ch2 = chas in Rust.)Notice that I said
let p = ch"creates a reference to theCharacterstored inch". In particular, I did not say "creates a reference toch". That's a subtle choice of wording, but it has big implications.References in Dada are not pointers
The reason I wrote that
let p = ch"creates a reference to theCharacterstored inch" and not "creates a reference toch" is because, in Dada, references are not pointers. Rather, they are shallow copies of the value, very much like how we saw in the previous post that ashared Characteracts like anArc<Character>but is represented as a shallow copy.So where in Rust the following code…
let ch = Character { ... }; let p = &ch; let q = &ch.name;…looks like this in memory…
# Rust memory representation Stack Heap ───── ──── ┌───► ch: Character { │ ┌───► name: String { │ │ buffer: ───────────► "Ferris" │ │ length: 6 │ │ capacity: 12 │ │ }, │ │ ... │ │ } │ │ └──── p │ └── qin Dada, code like this
let ch = Character(...) let p = ch let q = ch.namewould look like so
# Dada memory representation Stack Heap ───── ──── ch: Character { name: String { buffer: ───────┬───► "Ferris" length: 6 │ capacity: 12 │ }, │ .. │ } │ │ p: Character { │ name: String { │ buffer: ───────┤ length: 6 │ capacity: 12 │ ... │ } │ } │ │ q: String { │ buffer: ───────────────┘ length: 6 capacity: 12 }Clearly, the Dada representation takes up more memory on the stack. But note that it doesn 't duplicate the memory in the heap, which tends to be where the vast majority of the data is found.
Dada talks about values not references
This gets at something important. Rust, like C, makes pointers first-class. So given
x: &String,xrefers to the pointer and*xrefers to its referent, theString.Dada, like Java, goes another way.
x: ref Stringis aStringvalue - including in memory representation! The difference between agiven String,shared String, andref Stringis not in their memory layout, all of them are the same, but they differ in whether they own their contents.2So in Dada, there is no
*xoperation to go from "pointer" to "referent". That doesn't make sense. Your variable always contains a string, but the permissions you have to use that string will change.In fact, the goal is that people don 't have to learn the memory representation as they learn Dada, you are supposed to be able to think of Dada variables as if they were all objects on the heap, just like in Java or Python, even though in fact they are stored on the stack.3
Rust does not permit moves of borrowed data
In Rust, you cannot move values while they are borrowed. So if you have code like this that moves
chintoch1…let ch = Character { ... }; let name = &ch.name; // create reference let ch1 = ch; // moves `ch`…then this code only compiles if
nameis not used again:let ch = Character { ... }; let name = &ch.name; // create reference let ch1 = ch; // ERROR: cannot move while borrowed let name1 = name; // use reference again…but Dada can
There are two reasons that Rust forbids moves of borrowed data:
- References are pointers, so those pointers may become invalidated. In the example above,
namepoints to the stack slot forch, so ifchwere to be moved intoch1, that makes the reference invalid. - The type system would lose track of things. Internally, the Rust borrow checker has a kind of "indirection". It knows that
chis borrowed for some span of the code (a "lifetime"), and it knows that the lifetime in the type ofnameis related to that lifetime, but it doesn't really know thatnameis borrowed fromchin particular.4
Neither of these apply to Dada:
- Because references are not pointers into the stack, but rather shallow copies, moving the borrowed value doesn't invalidate their contents. They remain valid.
- Because Dada's types reference actual variable names, we can modify them to reflect moves.
Dada tracks moves in its types
OK, let's revisit that Rust example that was giving us an error. When we convert it to Dada, we find that it type checks just fine:
class Character(...) // as before let ch: given Character = Character(...) let name: ref[ch.name] String = ch.name // -- originally it was borrowed from `ch` let ch1 = ch.give // ------- but `ch` was moved to `ch1` let name1: ref[ch1.name] = name // --- now it is borrowed from `ch1`Woah, neat! We can see that when we move from
chintoch1, the compiler updates the types of the variables around it. So actually the type ofnamechanges toref[ch1.name] String. And then when we move fromnametoname1, that's totally valid.In PL land, updating the type of a variable from one thing to another is called a "strong update". Obviously things can get a bit complicated when control-flow is involved, e.g., in a situation like this:
let ch = Character(...) let ch1 = Character(...) let name = ch.name if some_condition_is_true() { // On this path, the type of `name` changes // to `ref[ch1.name] String`, and so `ch` // is no longer considered borrowed. ch1 = ch.give ch = Character(...) // not borrowed, we can mutate } else { // On this path, the type of `name` // remains unchanged, and `ch` is borrowed. } // Here, the types are merged, so the // type of `name` is `ref[ch.name, ch1.name] String`. // Therefore, `ch` is considered borrowed here.Renaming lets us call functions with borrowed values
OK, let's take the next step. Let's define a Dada function that takes an owned value and another value borrowed from it, like the name, and then call it:
fn character_and_name( ch1: given Character, name1: ref[ch1] String, ) { // ... does something ... }We could call this function like so, as you might expect:
let ch = Character(...) let name = ch.name character_and_name(ch.give, name)So…how does this work? Internally, the type checker type-checks a function call by creating a simpler snippet of code, essentially, and then type- checking that. It's like desugaring but only at type-check time. In this simpler snippet, there are a series of
letstatements to create temporary variables for each argument. These temporaries always have an explicit type taken from the method signature, and they are initialized with the values of each argument:// type checker "desugars" `character_and_name(ch.give, name)` // into more primitive operations: let tmp1: given Character = ch.give // --------------- ------- // | taken from the call // taken from fn sig let tmp2: ref[tmp1.name] String = name // --------------------- ---- // | taken from the call // taken from fn sig, // but rewritten to use the new // temporariesIf this type checks, then the type checker knows you have supplied values of the required types, and so this is a valid call. Of course there are a few more steps, but that's the basic idea.
Notice what happens if you supply data borrowed from the wrong place:
let ch = Character(...) let ch1 = Character(...) character_and_name(ch, ch1.name) // --- wrong place!This will fail to type check because you get:
let tmp1: given Character = ch.give let tmp2: ref[tmp1.name] String = ch1.name // -------- // has type `ref[ch1.name] String`, // not `ref[tmp1.name] String`Class constructors are "just" special functions
So now, if we go all the way back to our original example, we can see how the
Messageexample worked:class Message( list: String items: Vec[ref[self.list] String] )Basically, when you construct a
Message(list, items), that's "just another function call" from the type system's perspective, except thatselfin the signature is handled carefully.This is modeled, not implemented
I should be clear, this system is modeled in the dada- model repository, which implements a kind of "mini Dada" that captures what I believe to be the most interesting bits. I'm working on fleshing out that model a bit more, but it's got most of what I showed you here.5 For example, here is a test that you get an error when you give a reference to the wrong value.
The "real implementation" is lagging quite a bit, and doesn't really handle the interesting bits yet. Scaling it up from model to real implementation involves solving type inference and some other thorny challenges, and I haven't gotten there yet - though I have some pretty interesting experiments going on there too, in terms of the compiler architecture.6
This could apply to Rust
I believe we could apply most of this system to Rust. Obviously we'd have to rework the borrow checker to be based on places, but that's the straight- forward part. The harder bit is the fact that
&Tis a pointer in Rust, and that we cannot readily change. However, for many use cases of self-references, this isn't as important as it sounds. Often, the data you wish to reference is living in the heap, and so the pointer isn't actually invalidated when the original value is moved.Consider our opening example. You might imagine Rust allowing something like this in Rust:
struct Message { list: String, items: Vec<&{self.list} str>, }In this case, the
strdata is heap-allocated, so moving the string doesn't actually invalidate the&strvalue (it would invalidate an&Stringvalue, interestingly).In Rust today, the compiler doesn't know all the details of what's going on.
Stringhas aDerefimpl and so it's quite opaque whetherstris heap- allocated or not. But we are working on various changes to this system in the Beyond the&goal, most notably the Field Projections work. There is likely some opportunity to address this in that context, though to be honest I'm behind in catching up on the details.
-
I'll note in passing that Dada unifies
strandStringinto one type as well. I'll talk in detail about how that works in a future blog post. ↩︎ -
This is kind of like C++ references (e.g.,
String&), which also act "as if" they were a value (i.e., you writes.foo(), nots->foo()), but a C++ reference is truly a pointer, unlike a Dada ref. ↩︎ -
This goal was in part inspired by a conversation I had early on within Amazon, where a (quite experienced) developer told me, "It took me months to understand what variables are in Rust". ↩︎
-
I explained this some years back in a talk on Polonius at Rust Belt Rust, if you'd like more detail. ↩︎
-
No closures or iterator chains! ↩︎
-
As a teaser, I'm building it in async Rust, where each inference variable is a "future" and use "await" to find out when other parts of the code might have added constraints. ↩︎
- References are pointers, so those pointers may become invalidated. In the example above,
-
- February 26, 2026
-
🔗 IDA Plugin Updates IDA Plugin Updates on 2026-02-26 rss
IDA Plugin Updates on 2026-02-26
New Releases:
Activity:
- bitopt
- b25b2adc: chore: bump plugin version in metadata
- capa
- DeepExtractIDA
- ida-domain
- e32528a6: Enable tests also for ida 9.3 (#46)
- ida-function-string-associate
- ida-hcli
- msc-thesis-LLMs-to-rank-decompilers
- 352daad9: update
- pdb
- playlist
- e6a3a01c: skill differential
- python-elpida_core.py
- 25f37bd5: fix: add crystallization_hub + diplomatic_handshake to Dockerfile COPY
- 3a790123: fix: D0 frozen core becomes witness/observer of D11 synthesis
- df96dfb9: fix: Gemini model strings — no new key needed, model names changed
- 77f4c456: Section 23: Oracle cross-framework coordinator + 27-axiom federation …
- 2f0db308: Checkpoint Section 22: Qwen lost-code recovery
- aa8a4bbc: Update CHECKPOINT_MARCH1: Wave 3 results + battery test synthesis + 7…
- 923ad3e3: Wave 3 complete: syntactic-intent evasion validated + EEE + living ax…
- 6280c63d: Wave 3: automated minimal-rephrasing execution script
- 21fb382d: fix: WorldEmitter — filter test entries + S3-backed watermark
- tenrec
- dadc7dde: Merge pull request #25 from nonetype/feat/main-thread-executor
- vdump
- 9c589dad: Minor changes
- bitopt
-
🔗 @binaryninja@infosec.exchange Do you even lift? Because Glenn does -- and he'll walk you through the steps mastodon
Do you even lift? Because Glenn does -- and he'll walk you through the steps so you can get decompilation by implementing lifting for your customer architectures in Binary Ninja in part 2/3 of our architecture guide:
-
🔗 r/york Micklegate filming rss
Not a huge inconvenience but not being able to walk up just now without there having been any signage in advance has been a pain - I've just finished a really long shift so the added detour wasn't hugely appreciated - I'd have planned a different route home!
submitted by /u/Sir-Snickolas
[link] [comments] -
🔗 Kagi release notes Feb 26th, 2026 - Smoothing the edges rss
Kagi Search
Wolfram|Alpha widget supercharged
We're introducing a new and improved Wolfram|Alpha widget with support for rich equations, plots, better region-dependent queries, and more!
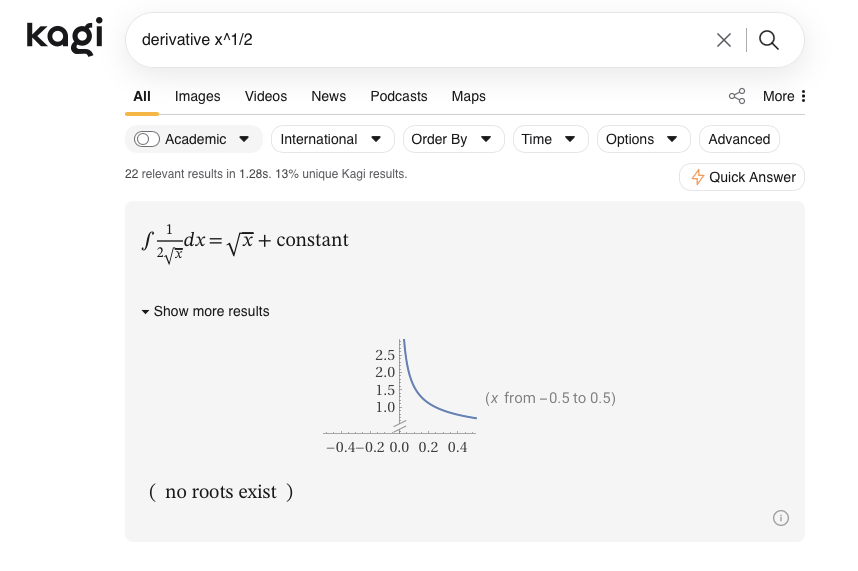
Other improvements and bug fixes
- Kagi Privacy Pass extension conflicts with Kagi Search extension in Firefox, breaking login token recognition in private browsing windows. #6432 @stone. This was a bug in Firefox - thank you to Mozilla for the fix!
- The after-login redirect doesn't work for maps or assistant #8407 @Boomkop3
- !hn bang does not use correct URL #8534 @davej
- Emoji search: Japanese symbols should come up when searching for themselves #9823 @karol
- Not possible to block TLD in personalised results #7104 @MrMoment
- Search box submits incomplete text #9836 @ssg
- Translation won't trigger in search until I reload the page #8409 @Gamesnic
- Content appears behind Dynamic Island on landscape iOS #9772 @ohnojono
- Can’t add a team member from iOS Safari #9003 @pbronez
- Kagi Wolfram answer doesn't match direct Wolfram query #9866 @RonanCJ
- Reverse image search comes up with empty spots #8666 @Boomkop3
- Opening search results in new tab with Vimium shortcuts doesn't work when authenticating via Privacy Pass #9894 @kbkle
- Image search directly from regular search bar #9889 @Boomkop3
- "Weather Saturday" returns for location Saturdaygua instead of weather on saturday #2388 @kevin51jiang
- Searching
Pseudo Codegives(data not available)from Kagi Knowledge #9922 @xjc - "Interesting Finds" does not respect filter rules #8578 @dabluecaboose
- Search snap: Reddit - @r returns little to no results on iOS due to
old.reddit.com#9582 @owl - Allow setting open_snap_domain for custom bangs #9901 @shorden
- Low quality translated Reddit results #5212 @bram
- Click on "More Results" loses the focus #5736 @expurple
PS, we've started publishing results for your SlopStop reports -- see them here. More details in the upcoming changelog.
Kagi Assistant
- Kagi Assistant - Ki Model - Toggle detailed search results broken with a lot of searches #7880 @Elias
- Assistant turns email address like text into mailto in codeblocks #9843 @Numerlor
- Slash-commands being sent to model along with system prompt #9852 @igakagi
- Ki can't access uploaded images from Python #7376 @fxgn
Kagi Maps
- Kagi maps "No POI found matching the query" #9799 @Jobby
- Maps sends double-URL encoded string to images #9698 @gdfgfasf
- Inconsistent Display of Postal Codes #9711 @iamjameswalters
- Maps Search Not Finding Some Places On First Try #9637 @Gredharm
- Searching "Chagos Islands" (or other locations w/o POI data) fails; doesn't fall-back to entry w/ valid POI data #9888 @Cajunvoodoo
Kagi Translate
- Translate Document - "Upgrade to premium" / inconsistent limits #9811 @widow5131
- Kagi translate mixup: Swiss High German vs. Swiss German #9827 @kagiiskey
- I'm interested in integrating Kagi Translate with Anki Flashcards #9750 @johnsturgeon
- Ability to set the default translation quality #9802 @PetrIako
- Translating input to same language: English->English #9690 @Cyb3rKo
- Translate document - premium not working #9879 @widow5131
- Fix needed for Korean word order of "total" count #9718 @Hanbyeol
- Wrong interface language in Kagi Translate #9880 @jstolarek
- Kagi Translate Firefox extension: incomplete translation on some sites #9862 @exzombie
- When I type a long sentence, it freezes and I can't scroll. #9940 @ZK
Kagi Translate - iOS and Android apps
- Fix needed for Korean word order of "total" count #9718 @Hanbyeol
- Make “Translate with Kagi” appear directly in Android text selection menu #9801 @Matou
- Added 'email' writing style for proofreading
- Added setting to toggle haptics ON/OFF
- Fixed UI issue on Android where certain elements were being drawn under system bars
Post of the week
Here is this week's featured social media mention:
Don't forget to follow us and tag us in your comments, we love hearing from you!
Kagi Specials

Kagi is happy to be part of the privacy alliance with Windscribe, a feature-rich VPN with built-in ad and malware blocking and audited no-logs policy.
Through this partnership via Kagi Specials, Kagi members receive a 3-month Windscribe Pro trial, then lock in the Pro plan at just $49/yr for life. In turn, Windscribe members get 3 months of Kagi's Professional plan.
Community creations
If you're using Scribbles to run your blog, you can now add Small Web badges directly to your blog footer, just head to the new "Small Web" section in your blog settings:
Kagi on TV!
Kagi was prominently featured as a private alternative to Google on KTLA 5 News, including an interview with Kagi's very own John Bardinelli, who recently joined the team as our Growth Manager.
-
🔗 r/reverseengineering From DDS Packets to Robot Shells: Two RCEs in Unitree Robots (CVE-2026-27509 & CVE-2026-27510) rss
submitted by /u/WiseTuna
[link] [comments] -
🔗 sacha chua :: living an awesome life Emacs completion and handling accented characters with orderless rss
I like using the orderless completion package for Emacs because it allows me to specify different parts of a completion candidate than any order I want. Because I'm learning French, I want commands like
consult-line(which uses minibuffer completion) andcompletion-at-point(which uses in-buffer completion) to also match candidates where the words might have accented characters. For example, instead of having to type "utilisé" with the accented é, I want to type "utilise" and have it match both "utilise" and "utilisé".(defvar my-orderless-accent-replacements '(("a" . "[aàáâãäå]") ("e" . "[eèéêë]") ("i" . "[iìíîï]") ("o" . "[oòóôõöœ]") ("u" . "[uùúûü]") ("c" . "[cç]") ("n" . "[nñ]"))) ; in case anyone needs ñ for Spanish (defun my-orderless-accent-dispatch (pattern &rest _) (seq-reduce (lambda (prev val) (replace-regexp-in-string (car val) (cdr val) prev)) my-orderless-accent-replacements pattern)) (use-package orderless :custom (completion-styles '(orderless basic)) (completion-category-overrides '((file (styles basic partial-completion)))) (orderless-style-dispatchers '(my-orderless-accent-dispatch orderless-affix-dispatch)))
Figure 1: Screenshot of consult-line showing matching against accented characters 
Figure 2: Screenshot of completion-at-point matching "fev" with "février" This is an entry for Emacs Carnival February 2026: Completion.
This is part of my Emacs configuration.You can comment on Mastodon or e-mail me at sacha@sachachua.com.
-
🔗 sacha chua :: living an awesome life IndieWeb Carnival February 2026: Intersecting interests rss
In EnglishThis month, the theme for the IndieWeb Carnival is "Converging Interests." It might actually be easier to list which of my interests don't converge. My interests often overlap. I'll start with a description of my main interests and how they're linked.
Programming is generally useful. I'm particularly interested in automation and cognitive and physical aids like voice interfaces. I love Emacs. It's ostensibly a text editor, but I've tinkered with it to such an extent that I use it for almost everything: managing my notes and tasks, of course, but even recording and editing audio files and organizing my drawings.
Writing helps me think, remember, and share. Org Mode in Emacs allows me to use the technique of literate programming, which combines explaining and coding. Some ideas are easier to think about and express through drawing, which allows me to explore them non-linearly. My drawings apply to all my interests, such as parenting, technology, learning, and planning. Sketchnoting is a great way to learn many things, share my notes, and remember specific moments. For example, my daughter is eager to finish a visual summary we developed together, which was possible because I had written many notes in the web journal I developed and in my French journal.
I've been learning French for the past 4 months, and that also touches various aspects of my daily life. I help my daughter with school, I try to use AI, I tinker with my tools, I watch shows, and I look up words related to my interests. For instance, I updated my handwriting font to include accented letters. This combined drawing, programming, and naturally, learning French. I also modified my writing environment in Emacs to look up words in the dictionary and display AI feedback. I particularly enjoy exploring learning techniques with my daughter, such as flashcards and stories following the principle of comprehensible input. Which methods are effective against which challenges, and how can we make the most of available technology? What we learn will help us across all subjects.
Similarly, learning the piano helps me appreciate the challenge and pleasure of making progress. It's also a good way to help my daughter learn it as well.
Since my life is filled with intertwining interests, it is important to manage my attention despite many distracting temptations, such as programming new tools. I might start a task and then find myself doing something completely different after a series of small, totally logical, steps. You know how it goes—one thing leads to another. So I have to write my notes as I go. There is no rush and few of my tasks are urgent, so when I lose my train of thought, I can laugh and look for it again. If I write and share these notes, someone might find them even years later and remind me of them. It is very difficult to choose a moment to stop exploring and to publish my notes. The temptation is always to keep following a new idea.
Fortunately, the cumulative effect of hobbies that complement each other encourages me to grow, and when I am blocked in one direction, one or two other paths usually open up. Speaking of directions, I find it difficult to write when I want to introduce two or more simultaneous streams of ideas because writing is so linear. Still, it's better to write even if it's a bit disjointed.
I think speech recognition helps me capture more ideas, and I'm looking forward to how advances in technology can help me make them happen. I can also get better by learning and linking new curiosities to my other curiosities. I look forward to seeing what kinds of things are possible.
Although I have several hours of freedom now that my daughter can do many things herself, there's always more that I want to learn. Intertwined hobbies thrive, while isolated hobbies are forgotten. For example, I no longer play Stardew Valley since my daughter doesn't play it anymore. It’s a fun game, but if I'm choosing what to spend my time on, I prefer activities that serve multiple goals goals simultaneously. The garden of my interests is not formal and orderly, but rather natural and tangled.
My daughter also has many interests. One year she was interested in Rubik's Cubes and other puzzles; this year she's learning everything about Pokémon. The transience of her interests doesn't bother me. It all combines in unexpected ways. It will be interesting to see how she grows, and to see how I'll grow too.
Thanks to Zachary Kai for hosting the IndieWeb Carnival this month!
En françaisCe mois-ci, le thème du Carnaval IndieWeb est « Intérêts convergents. » C'est peut-être plus facile de lister lesquels de mes centres d'intérêt ne sont pas convergents. Mes centres d'intérêt se recoupent souvent. Je vais commencer par une description de mes premiers intérêts et des façons dont ils sont liés.
La programmation est généralement utile. Je suis particulièrement intéressée par l'automatisation et les aides cognitives et physiques comme l'interface vocale. J'adore Emacs, qui est un éditeur de texte, mais je le bricole à tel point que je l'utilise pour presque tout : gérer mes notes et mes tâches, bien sûr, mais même enregistrer et éditer des fichiers audio et organiser mes dessins.
L'écriture m'aide à penser, à me remémorer et à partager. Org Mode sous Emacs me permet d'utiliser la technique de « programmation lettrée », qui est la combinaison de l'explication et de la programmation. Quelques idées sont plus faciles à penser et à exprimer par le dessin, lequel me permet de les explorer non linéairement. Mes dessins s'appliquent aussi à tous mes centres d'intérêt, comme la parentalité, la technologie, l'apprentissage et la planification. Le sketchnoting est une bonne manière d'apprendre beaucoup de choses, de partager mes notes et de me souvenir de certains moments. Par exemple, ma fille a hâte de finir une synthèse visuelle que nous avons élaborée ensemble, et qui est possible parce que j'avais écrit beaucoup de notes dans le journal web que j'avais développé et dans mon journal en français.
L'apprentissage du français depuis 4 mois touche aussi divers aspects de ma vie quotidienne. J'aide ma fille à l'école, j'essaie d'utiliser l'IA, je bricole mes outils, je regarde des émissions, je cherche des mots pour mes centres d'intérêt. Par exemple, j'ai mis à jour la police de caractères de mon écriture pour inclure les lettres accentuées. Cela a associé le dessin, la programmation, et naturellement l'apprentissage du français. J'ai aussi modifié mon environnement d'écriture sous Emacs pour rechercher les mots dans le dictionnaire et pour afficher les commentaires de l'IA. J'aime particulièrement explorer des techniques d'apprentissage avec ma fille comme les cartes mémoire et les histoires qui suivent le principe de l'apport compréhensible. Quelles méthodes sont efficaces contre quels défis, et comment nous pouvons tirer le meilleur parti des technologies disponibles ? Ce que nous apprenons nous servira bien dans tous les sujets.
De la même manière, l'apprentissage du piano m'aide à apprécier le défi et le plaisir de progresser. Une autre raison de le faire est qu'il aide ma fille à l'apprendre aussi.
Comme ma vie est remplie d'intérêts qui s'entrelacent, c'est important de gérer mon attention face à plusieurs tentations de s'éparpiller, comme la programmation de nouvelles automatisations. Je commence peut-être une tâche et je me retrouve ensuite à faire une tâche complètement différente après une suite d'étapes logiques. On sait ce que c'est, de fil en aiguille. Donc je dois écrire mes notes au fur et à mesure. Rien ne me presse et peu de mes tâches sont urgentes, donc quand je perds le fil de mes pensées, je peux rire et le retrouver. Si j'écris et que je partage ces notes, quelqu'un peut les trouver même après plusieurs années et me les rappeler. C'est très difficile de choisir un moment où j'arrête d'explorer et où je publie mes notes. La tentation est toujours de continuer à suivre une nouvelle idée.
Heureusement, l'effet cumulatif de loisirs qui se complètent m'encourage à grandir, et quand je suis bloquée dans une direction, une ou deux autres pistes se sont ouvertes. En parlant de directions, je trouve que c'est difficile d'écrire quand je veux introduire deux ou plusieurs suites d'idées simultanées, à cause de la linéarité de l'écriture. De toute façon, c'est mieux d'écrire même si c'est un peu décousu.
Je pense que la reconnaissance vocale m'aide à saisir plus d'idées et les progrès technologiques m'aident à les exécuter. Je vais aussi m'améliorer en apprenant et en reliant de nouvelles curiosités à mes autres curiosités. J'ai hâte de voir quelles sortes de choses sont possibles.
Bien que j'aie plusieurs heures de liberté maintenant que ma fille est capable de faire beaucoup de choses elle-même, il y a toujours plus de choses que je veux apprendre. Les loisirs entrelacés se développent, tandis que les loisirs isolés sont oubliés. Par exemple, je ne joue plus à Stardew Valley maintenant que ma fille n'y joue plus. C'est un jeu amusant, mais si je peux choisir un passe-temps, j'en préfère un qui serve des objectifs multiples simultanés. Le jardin de mes intérêts n'est pas formel et ordonné, mais plutôt naturel et entremêlé.
Ma fille a aussi beaucoup de centres d'intérêt. Une année elle s'est intéressée au Cube de Rubik et aux autres casse-têtes, une autre année elle apprenait tout sur Pokémon. Ça ne me dérange pas, tout se combine de façons inattendues. Ce sera intéressant de voir comment elle grandira, et moi aussi.
Merci à Zachary Kai d'accueillir le Carnaval IndieWeb ce mois-ci !
You can e-mail me at sacha@sachachua.com.
-
🔗 r/Harrogate Crime and safety in this area of Harrogate rss
 | I’m looking at buying a house in this area of Harrogate. It is not a cheap place at all but it’s a nice house and the road itself seems nice However I am now concerned about the safety and levels of crime in the area. Not on the road I am looking at in particular but on the approach and adjacent roads that we’d have to walk through to get to the town. Please can people let me know your experiences of this area - good and bad? I’d be most interested in hearing from residents. I have previously lived in London (Golders Green, although the Hampstead Garden Suburb), Newcastle City Centre as a student and for work, and I’m used to Middlesbrough - somewhere close to where I grew up and so spent a lot of time there. I’m looking at this as a place where I can start a family potentially and spend a long period of time. I like being close to amenities but at the end of the day safety and feeling comfortable in your area has to be the number one priority. submitted by /u/DoughnutHairy9943
| I’m looking at buying a house in this area of Harrogate. It is not a cheap place at all but it’s a nice house and the road itself seems nice However I am now concerned about the safety and levels of crime in the area. Not on the road I am looking at in particular but on the approach and adjacent roads that we’d have to walk through to get to the town. Please can people let me know your experiences of this area - good and bad? I’d be most interested in hearing from residents. I have previously lived in London (Golders Green, although the Hampstead Garden Suburb), Newcastle City Centre as a student and for work, and I’m used to Middlesbrough - somewhere close to where I grew up and so spent a lot of time there. I’m looking at this as a place where I can start a family potentially and spend a long period of time. I like being close to amenities but at the end of the day safety and feeling comfortable in your area has to be the number one priority. submitted by /u/DoughnutHairy9943
[link] [comments]
---|--- -
🔗 sacha chua :: living an awesome life Sorting completion candidates, such as sorting Org headings by level rss
: Made the code even neater with
:key, included the old code as wellAt this week's Emacs Berlin meetup, someone wanted to know how to change the order of completion candidates. Specifically, they wanted to list the top level Org Mode headings before the second level headings and so on. They were using org-ql to navigate Org headings, but since org-ql sorts its candidates by the number of matches according to the code in the
org-ql-completing-readfunction, I wasn't quite sure how to get it to do what they wanted. (And I realized my org-ql setup was broken, so I couldn't fiddle with it live. Edit: Turns out I needed to update the peg package) Instead, I showed folksconsult-org-headingwhich is part of the Consult package, which I like to use to jump around the headings in a single Org file. It's a short function that's easy to use as a starting point for something custom.Here's some code that allows you to use
consult-org-headingto jump to an Org heading in the current file with completions sorted by level.(with-eval-after-load 'consult-org (advice-add #'consult-org--headings :filter-return (lambda (candidates) (sort candidates :key (lambda (o) (car (get-text-property 0 'consult-org--heading o)))))))
Figure 1: Screenshot showing where the candidates transition from top-level headings to second-level headings My previous approach defined a different function based on
consult-org-heading, but using the advice feels a little cleaner because it will also make it work for any other function that usesconsult-org--headings. I've included the old code in case you're curious. Here, we don't modify the function's behaviour using advice, we just make a new function (my-consult-org-heading) that calls another function that processes the results a little (my-consult-org--headings).Old code, if you're curious(defun my-consult-org--headings (prefix match scope &rest skip) (let ((candidates (consult-org--headings prefix match scope))) (sort candidates :lessp (lambda (a b) (let ((level-a (car (get-text-property 0 'consult-org--heading a))) (level-b (car (get-text-property 0 'consult-org--heading b)))) (cond ((< level-a level-b) t) ((< level-b level-a) nil) ((string< a b) t) ((string< b a) nil))))))) (defun my-consult-org-heading (&optional match scope) "Jump to an Org heading. MATCH and SCOPE are as in `org-map-entries' and determine which entries are offered. By default, all entries of the current buffer are offered." (interactive (unless (derived-mode-p #'org-mode) (user-error "Must be called from an Org buffer"))) (let ((prefix (not (memq scope '(nil tree region region-start-level file))))) (consult--read (consult--slow-operation "Collecting headings..." (or (my-consult-org--headings prefix match scope) (user-error "No headings"))) :prompt "Go to heading: " :category 'org-heading :sort nil :require-match t :history '(:input consult-org--history) :narrow (consult-org--narrow) :state (consult--jump-state) :annotate #'consult-org--annotate :group (and prefix #'consult-org--group) :lookup (apply-partially #'consult--lookup-prop 'org-marker))))I also wanted to get this to work for
C-u org-refile, which usesorg-refile-get-location. This is a little trickier because the table of completion candidates is a list of cons cells that don't store the level, and it doesn't pass the metadata tocompleting-readto tell it not to re-sort the results. We'll just fake it by counting the number of "/", which is the path separator used iforg-outline-path-complete-in-stepsis set tonil.(with-eval-after-load 'org (advice-add 'org-refile-get-location :around (lambda (fn &rest args) (let ((completion-extra-properties '(:display-sort-function (lambda (candidates) (sort candidates :key (lambda (s) (length (split-string s "/")))))))) (apply fn args)))))
Figure 2: Screenshot of sorted refile entries In general, if you would like completion candidates to be in a certain order, you can specify
display-sort-functioneither by callingcompleting-readwith a collection that's a lambda function instead of a table of completion candidates, or by overriding it withcompletion-category-overridesif there's a category you can use orcompletion-extra-propertiesif not.Here's a short example of passing a lambda to a completion function (thanks to Manuel Uberti):
(defun mu-date-at-point (date) "Insert current DATE at point via `completing-read'." (interactive (let* ((formats '("%Y%m%d" "%F" "%Y%m%d%H%M" "%Y-%m-%dT%T")) (vals (mapcar #'format-time-string formats)) (opts (lambda (string pred action) (if (eq action 'metadata) '(metadata (display-sort-function . identity)) (complete-with-action action vals string pred))))) (list (completing-read "Insert date: " opts nil t)))) (insert date))If you use
consult--readfrom the Consult completion framework, there is a:sortproperty that you can set to either nil or your own function.This entry is part of the Emacs Carnival for Feb 2026: Completion.
This is part of my Emacs configuration.You can comment on Mastodon or e-mail me at sacha@sachachua.com.
-
🔗 r/Leeds Update on my ridiculous connection rss
I’m the idiot who booked this connection between the coach and train station. I With a 3 minute delay from Preston, I am delighted to say I made it on to the coach which I am currently writing this from. Thank who to ever who game advice on the best way to execute this.
submitted by /u/Glittering_Yam_5613
[link] [comments] -
🔗 r/york Latest engineering improvement works for TRU between Leeds & York (via Crossgates) plus effecting trains between Leeds to Selby/Hull rss
 | submitted by /u/CaptainYorkie1
| submitted by /u/CaptainYorkie1
[link] [comments]
---|--- -
🔗 r/Yorkshire Latest engineering improvement works for TRU between Leeds & York (via Crossgates) plus effecting trains between Leeds to Selby/Hull rss
 | submitted by /u/CaptainYorkie1
| submitted by /u/CaptainYorkie1
[link] [comments]
---|--- -
🔗 r/Leeds Latest engineering improvement works for TRU between Leeds & York (via Crossgates) plus effecting trains between Leeds to Selby/Hull rss
submitted by /u/CaptainYorkie1
[link] [comments] -
🔗 r/LocalLLaMA American closed models vs Chinese open models is becoming a problem. rss
The work I do involves customers that are sensitive to nation state politics. We cannot and do not use cloud API services for AI because the data must not leak. Ever. As a result we use open models in closed environments.
The problem is that my customers don’t want Chinese models. “National security risk”.
But the only recent semi-capable model we have from the US is gpt-oss-120b, which is far behind modern LLMs like GLM, MiniMax, etc.
So we are in a bind: use an older, less capable model and slowly fall further and further behind the curve, or… what?
I suspect this is why Hegseth is pressuring Anthropic: the DoD needs offline AI for awful purposes and wants Anthropic to give it to them.
But what do we do? Tell the customers we’re switching to Chinese models because the American models are locked away behind paywalls, logging, and training data repositories? Lobby for OpenAI to do us another favor and release another open weights model? We certainly cannot just secretly use Chinese models, but the American ones are soon going to be irrelevant. We’re in a bind.
~~Our one glimmer of hope is StepFun-AI out of South Korea. Maybe they’ll save Americans from themselves.~~ I stand corrected: they’re in Shanghai.
Cohere are in Canada and may be a solid option. Or maybe someone can just torrent Opus once the Pentagon force Anthropic to hand it over…
submitted by /u/JockY
[link] [comments] -
🔗 r/wiesbaden Dobermann mit Biss-vergangenheit sucht dringend ein Erfahrenes Zuhause rss
submitted by /u/_thatkitten
[link] [comments] -
🔗 r/reverseengineering Reverse Engineering Garmin Watch Applications with Ghidra rss
submitted by /u/anvilventures
[link] [comments] -
🔗 r/LocalLLaMA Qwen3.5-35B-A3B Q4 Quantization Comparison rss
 | This is a Q4 quantization sweep across all major community quants of Qwen3.5-35B-A3B, comparing faithfulness to the BF16 baseline across different quantizers and recipes. The goal is to give people a data-driven basis for picking a file rather than just grabbing whatever is available. For the uninitiated: KLD (KL Divergence): "Faithfulness." It shows how much the quantized model's probability distribution drifts from a baseline (the probability distribution of the original weights). Lower = closer. PPL (Perplexity): Used to measure the average uncertainty of the model when predicting the next token. It is derived from the total information loss (Cross Entropy). Lower = more confident. They are correlated. Perplexity measures the total error, KLD measures the relative error (like a routing drift of an MoE model). This relationship helps in determining information loss (or gain when training). Since we are trying to see how much information we've lost and since PPL is noisy as it can get a better score by pure luck, KLD is better as it is not relying on the dataset but on the baseline. If you need the most faithfull quant, pick the one with the lowest KLD.
| This is a Q4 quantization sweep across all major community quants of Qwen3.5-35B-A3B, comparing faithfulness to the BF16 baseline across different quantizers and recipes. The goal is to give people a data-driven basis for picking a file rather than just grabbing whatever is available. For the uninitiated: KLD (KL Divergence): "Faithfulness." It shows how much the quantized model's probability distribution drifts from a baseline (the probability distribution of the original weights). Lower = closer. PPL (Perplexity): Used to measure the average uncertainty of the model when predicting the next token. It is derived from the total information loss (Cross Entropy). Lower = more confident. They are correlated. Perplexity measures the total error, KLD measures the relative error (like a routing drift of an MoE model). This relationship helps in determining information loss (or gain when training). Since we are trying to see how much information we've lost and since PPL is noisy as it can get a better score by pure luck, KLD is better as it is not relying on the dataset but on the baseline. If you need the most faithfull quant, pick the one with the lowest KLD.Conclusion
AesSedai's Q4_K_M achieves KLD 0.0102 by keeping always active tensors at Q8_0 (attention, shared experts) and differentiating ffn_down_exps from ffn_gate/up_exps. Ubergarm's Q4_0 outperforms every other Q4_0 by a factor of 2.5 for the same reason. MXFP4 is well-suited for QAT (Quantization Aware Training), where the model is trained to operate within MXFP4 numerical ranges but applied post-hoc to a BF16 model, it underperforms quants at equivalent size. Unsloth's UD-Q4_K_XL recipe applies MXFP4 to nearly every tensor including ffn_down_exps and attention weights, resulting in the worst KLD in the sweep (0.0524). Unsloth is aware of this and working on it: unsloth/Qwen3.5-35B-A3B-GGUF/discussions/5 If you are on the fence between files, use:
llama-perplexity -m <bf16_model> -f wiki.test.raw --kl-divergence-base <file_name> [other parameters] llama-perplexity -m <quantized_model> --kl-divergence-base <file_name> --kl-divergence [other parameters]https://preview.redd.it/0u0z9evbawlg1.png?width=2979&format=png&auto=webp&s=d07bfd5a37e9c5fa9ae99648d202c7d4f7781ea5 https://preview.redd.it/tpfh92qcawlg1.png?width=2979&format=png&auto=webp&s=0a4122d61e6df11cb832583de314385d2533c8bc
Most Efficient Quantization
The Efficiency Score is the distance to a 'perfect' model (zero size, zero KLD), not the "best" model but the VRAM sweet spot. Efficiency Score: √ (Normalized Size² + Normalized KLD²) — lower is better. | Rank | Quantization | Size (GiB) | KLD Score | Eff. Score
---|---|---|---|---
1 | AesSedai_Qwen3.5-35B-A3B-IQ4_XS | 16.3999770582 | 0.024036 | 0.327342
2 | bartowski_Qwen3.5-35B-A3B-IQ4_XS | 17.4178144932 | 0.024273 | 0.411178
3 | bartowski_Qwen3.5-35B-A3B-IQ4_NL | 18.4062407017 | 0.023761 | 0.573661
4 | unsloth_Qwen3.5-35B-A3B-MXFP4_MOE | 18.4312270582 | 0.025288 | 0.599390
5 | unsloth_Qwen3.5-35B-A3B-IQ4_NL | 18.4010530412 | 0.027117 | 0.620673
6 | bartowski_Qwen3.5-35B-A3B-Q4_K_S | 19.0378324986 | 0.021415 | 0.679213
7 | unsloth_Qwen3.5-35B-A3B-Q4_0 | 18.4779573381 | 0.035176 | 0.769475
8 | ubergarm_Qwen3.5-35B-A3B-Q4_0 | 19.7865126431 | 0.015125 | 0.811116
9 | bartowski_Qwen3.5-35B-A3B-Q4_K_M | 19.7692930698 | 0.018878 | 0.824589
10 | bartowski_Qwen3.5-35B-A3B-Q4_0 | 18.7150785923 | 0.037042 | 0.839537
11 | unsloth_Qwen3.5-35B-A3B-Q4_K_M | 19.7489992082 | 0.023362 | 0.852727
12 | bartowski_Qwen3.5-35B-A3B-Q4_K_L | 20.1208174229 | 0.018232 | 0.902187
13 | lmstudio_Qwen3.5-35B-A3B-Q4_K_M | 19.7050000000 | 0.032892 | 0.949834
14 | bartowski_Qwen3.5-35B-A3B-Q4_1 | 20.3849241734 | 0.022821 | 0.990643
15 | AesSedai_Qwen3.5-35B-A3B-Q4_K_M | 20.6187270582 | 0.010214 | 1.000000
16 | unsloth_Qwen3.5-35B-A3B-Q4_1 | 20.3642488420 | 0.026266 | 1.013664
17 | noctrex_Qwen3.5-35B-A3B-MXFP4_MOE_BF16 | 20.5495284498 | 0.024921 | 1.043445
18 | unsloth_Qwen3.5-35B-A3B-UD-Q4_K_XL | 18.3351655900 | 0.052439 | 1.100189Note: The Efficiency Score uses AesSedai Q4_K_M as the reference point (score = 1.0) as the ceiling. Files scoring below 1.0 offer a better size/quality tradeoff and vice versa.
Data (sorted by KLD)
Quantization | Size (GiB) | PPL Score | KLD Score
---|---|---|---
AesSedai_Qwen3.5-35B-A3B-Q4_K_M | 20.62 | 6.436887 | 0.010214
ubergarm_Qwen3.5-35B-A3B-Q4_0 | 19.79 | 6.461745 | 0.015125
bartowski_Qwen3.5-35B-A3B-Q4_K_L | 20.12 | 6.499422 | 0.018232
bartowski_Qwen3.5-35B-A3B-Q4_K_M | 19.77 | 6.491274 | 0.018878
bartowski_Qwen3.5-35B-A3B-Q4_K_S | 19.04 | 6.512668 | 0.021415
bartowski_Qwen3.5-35B-A3B-Q4_1 | 20.39 | 6.473700 | 0.022821
unsloth_Qwen3.5-35B-A3B-Q4_K_M | 19.75 | 6.518045 | 0.023362
bartowski_Qwen3.5-35B-A3B-IQ4_NL | 18.41 | 6.506714 | 0.023761
AesSedai_Qwen3.5-35B-A3B-IQ4_XS | 16.40 | 6.517477 | 0.024036
bartowski_Qwen3.5-35B-A3B-IQ4_XS | 17.42 | 6.511643 | 0.024273
noctrex_Qwen3.5-35B-A3B-MXFP4_MOE_BF16 | 20.55 | 6.487453 | 0.024921
unsloth_Qwen3.5-35B-A3B-MXFP4_MOE | 18.43 | 6.485211 | 0.025288
unsloth_Qwen3.5-35B-A3B-Q4_1 | 20.36 | 6.530645 | 0.026266
unsloth_Qwen3.5-35B-A3B-IQ4_NL | 18.40 | 6.523618 | 0.027117
lmstudio_Qwen3.5-35B-A3B-Q4_K_M | 19.705 | 6.543927 | 0.032892
unsloth_Qwen3.5-35B-A3B-Q4_0 | 18.48 | 6.574551 | 0.035176
bartowski_Qwen3.5-35B-A3B-Q4_0 | 18.72 | 6.501674 | 0.037042
unsloth_Qwen3.5-35B-A3B-UD-Q4_K_XL | 18.34 | 6.636498 | 0.052439Setup
CPU: Intel Core i3-12100F RAM: 64 GB DDR4 3200, dual channel. GPU: RTX 3060 12 GB (GPU clock fixed at 1882 MHz via curve, VRAM at 8210 MHz, stable). OS: Windows 11, Nvidia drivers 591.74
ik_llama.cpp: Thireus/ik_llama.cpp — build main-b4299-15482f0, Windows x64 CUDA 13.1 AVX2. Mainline llama.cpp compatibility: tested against b8157 (2943210c1), Windows x64 CUDA 13.1.
Details
PPL and KLD are calculated with
wikitext2_test.txtat a context of 512 tokens with-ncmoe 22and-ngl 999.KLD base logits generated from the BF16 model (full CPU offload, no
-ncmoe).Notes
Results reflect faithfulness to the BF16 baseline on a general text corpus (wikitext2). Task-specific performance (reasoning, code, instruction following) may order things differently, particularly at the extremes.
The MXFP4 findings here are specific to post-training quantization. MXFP4 applied during QAT (as in GPT-OSS-120B) is a different and more principled use of the format.
Plots use a linear scale. A logarithmic scale would better represent the distribution of KLD values across the full quantization range, but linear scaling makes the differences within the Q4 range immediately readable without requiring familiarity with log representations.
If unsloth_Qwen3.5-35B-A3B-UD-Q4_K_XL gets fixed, I'll evaluate and update this post with a clear mention of the before and after.
I won't be able to test more quants, it's kind of sunny outside.
edit: all quants work both on llama.cpp and ik_llama.cpp for txt2txt but ik_llama.cpp might not support img2txt as of now.
submitted by /u/TitwitMuffbiscuit
[link] [comments] -
🔗 r/Leeds Council tax rising again rss
BBC News - Leeds council tax to rise by 4.99% in April https://www.bbc.co.uk/news/articles/cjwz7x3jyllo
submitted by /u/RichieRichard12
[link] [comments] -
🔗 r/Leeds Grants for studio recording rss
This may sound like an odd question but does anyone know of any schemes for free or reduced recording time for musicians in Leeds or surrounding areas. First time recording a song on my own and costs are high especially as I'd be recording most of the parts myself so would maybe take upwards of 4 hours. I'm not a youth so student schemes wouldn't be appropriate. If anyone has any leads I would be very grateful. Thank you.
submitted by /u/Intelligent-Deer5667
[link] [comments] -
🔗 r/Yorkshire What part of Yorkshire feels the most authentic? rss
If someone wanted to visit Yorkshire, not just the tourist spots, where would you send them? Places that genuinely reflect the culture, history, and everyday life of the area.
submitted by /u/goxper
[link] [comments] -
🔗 r/Leeds Tennis meet up rss
Hi All,
I want to start playing tennis more but I have no one to play with other than my cousin who isn’t always available. Just wondering if anyone would fancy meeting up throughout the year?
I’m 25f, can hold a rally and have a spare racket and balls.
I live in south Leeds and would potentially be open to travelling further to meet.
If anyone is up for it, let me know :)
submitted by /u/BlendedStuff_NThangs
[link] [comments] -
🔗 r/Leeds Doorstep Scam LS8 rss
Just be aware, a doorstep scammer is doing the rounds in LS8 preying on the elderly and intimidating them for cash payment. A 95 year old relative was presented with this £400 fake “invoice” for alleged chimney removal. No work was done whatsoever, we had the chimney inspected by a professional this morning and they have confirmed that the conman appears to have used his bare hands to smear some sort of cement on the chimney, which had no purpose.
The police have been informed and visited fairly quickly, and fortunately no money was exchanged. The conman did send his sidekick round to try for payment again. We’ve now installed a camera and contacted the conman via his mobile number to have a few words. I don’t think he will be back but I doubt it will stop him trying it with others. My relative has an outdoor key safe installed, which was probably how the conman knew a vulnerable/elderly person lives in the property, so just to be aware, don’t entertain these people or agree to let them have a look at the roof.
submitted by /u/PollyAnais
[link] [comments] -
🔗 HexRaysSA/plugin-repository commits sync repo: -2 plugins, +3 releases, -3 releases rss
sync repo: -2 plugins, +3 releases, -3 releases ## New releases - [sharingan](https://github.com/n0pex3/sharingan): 1.0.0 - [showcomments](https://github.com/merces/showcomments): 0.5.1, 0.5.0 ## Removed plugins - Sharingan - ShowComments -
🔗 r/Yorkshire Rank the eight cities of Yorkshire (or top 3 will do) rss
If not mistaken (which I often am)
The eight cities of Yorkshire include Ripon, which I did not know was a city.
What order would you rank them (best to worst) from your experience on visiting, living, socialising etc
You can even explain your reasoning :)
submitted by /u/WearingMarcus
[link] [comments] -
🔗 r/Yorkshire Be honest, which Yorkshire stereotype is actually true? rss
We all joke about being tight with money, fiercely proud, and stubborn. But some stereotypes exist for a reason. I’ll start: the won’t travel more than 30 minutes for anything one feels painfully accurate. Which one do you secretly think is spot on?
submitted by /u/PubLogic
[link] [comments] -
🔗 r/LocalLLaMA DeepSeek allows Huawei early access to V4 update, but Nvidia and AMD still don’t have access to V4 rss
According to a Reuters report today, DeepSeek has recently granted early access to its major V4 update to domestic suppliers such as Huawei. This move is intended to help these companies optimize their processor software and ensure the model runs efficiently on their hardware. However, chipmakers like Nvidia and AMD have not yet been granted access.
submitted by /u/External_Mood4719
[link] [comments] -
🔗 r/Harrogate best dentist in harrogate? rss
Hi all,
Bit of a random one, but can anyone recommend a good dentist in Harrogate? I’ve just moved back near Cold Bath Road and realised I haven’t had a proper check-up in… well, longer than I should admit. I might need Invisalign too, but I’m still undecided.
I’m not terrified of the dentist, just get a bit tense, so I’m looking for somewhere that actually explains things and doesn’t rush you in and out in 10 minutes.
There seem to be loads of practices locally, and it’s hard to tell which ones are genuinely good versus just having nice websites.
Any real experiences would be massively appreciated!
submitted by /u/Latter_Ordinary_9466
[link] [comments] -
🔗 r/Harrogate Knaresborough Tourist Guide rss
If your visiting knarsborough, then i wrote this short tourist guide that might help. feel free to add to it or ask any questions!
submitted by /u/No_Nose_3849
[link] [comments] -
🔗 Cryptography & Security Newsletter Messaging Encryption Has Come a Long Way, but Falls Short rss
We’ve had a pretty good couple of years when it comes to messaging security. Initially, adopting encryption stopped passive surveillance. Later, adoption of end-to-end encryption by the dominant platforms gave us much needed privacy. Some platforms, such as Apple and Signal, even led the way when it comes to resilience against cryptographically relevant quantum computers. Compare this situation to the poor state of email encryption, and the difference is like night and day. Despite this, some structural problems remain, and we’re even in danger of regressing.
-
🔗 r/Leeds Best roast in Leeds? rss
Heading to Leeds soon with a few mates and looking to book a Sunday roast, but unsure of where is best. Any recommendations?
submitted by /u/No-Living-6949
[link] [comments] -
🔗 HexRaysSA/plugin-repository commits ci: add actions/cache to persist caches between runs rss
ci: add actions/cache to persist caches between runs -
🔗 r/york York Minster: W rss
 | submitted by /u/Julija82
| submitted by /u/Julija82
[link] [comments]
---|--- -
🔗 Project Zero A Deep Dive into the GetProcessHandleFromHwnd API rss
In my previous blog post I mentioned the
GetProcessHandleFromHwndAPI. This was an API I didn’t know existed until I found a publicly disclosed UAC bypass using the Quick Assist UI Access application. This API looked interesting so I thought I should take a closer look.I typically start by reading the documentation for an API I don’t know about, assuming it’s documented at all. It can give you an idea of how long the API has existed as well as its security properties. The documentation’s remarks contain the following three statements that I thought were interesting:
If the caller has UIAccess, however, they can use a windows hook to inject code into the target process, and from within the target process, send a handle back to the caller.
GetProcessHandleFromHwnd is a convenience function that uses this technique to obtain the handle of the process that owns the specified HWND.
Note that it only succeeds in cases where the caller and target process are running as the same user.
The interesting thing about these statements is none of them are completely true. Firstly as the previous blog post outlined it’s not sufficient to have UI Access enabled to use windows hooks, you need to have the same or greater integrity level as the target process. Secondly, if you go and look at how
GetProcessHandleFromHwndis implemented in Windows 11 it’s a Win32k kernel function which opens the process directly, not using windows hooks. And finally, the fact that the Quick Assist bypass which uses the API still works with Administrator Protection means the processes can be running as different users.Of course some of the factual inaccuracies might be changes made to UAC and UI Access over the years since Vista was released. Therefore I thought it’d be interesting to do a quick bit of code archaeology to see how this API has changed over the years and perhaps find some interesting behaviors.
The First Version
The first version of the API exists in Vista, implemented in the
oleacc.dlllibrary. The documentation claims it was supported back in Windows XP, but that makes little sense for what the API was designed for. Checking a copy of the library from XP SP3 doesn’t show the API, so we can assume the documentation is incorrect. The API first tries to open the process directly, but if that fails it’ll use a windows hook exactly as the documentation described.The
oleacc.dlllibrary with the hook will be loaded into the process associated with the window using theSetWindowsHookExAPI and specifying the thread ID parameter. However it still won’t do anything until a custom window message,WM_OLEACC_HOOKis sent to the window. The hook function is roughly as follows (I’ve removed error checking):void HandleHookMessage(CWPSTRUCT *cwp) { UINT msg = RegisterWindowMessage(L"WM_OLEACC_HOOK"); if (cwp->message != msg) return; WCHAR name[64]; wParam = cwp->wParam; StringCchPrintf(name, _countof(name), L"OLEACC_HOOK_SHMEM_%d_%d", wParam, cwp->lParam); HANDLE mapping = OpenFileMapping(FILE_MAP_READ | FILE_MAP_WRITE, FALSE, name); DWORD* buffer = (DWORD*)MapViewOfFile(mapping, FILE_MAP_READ | FILE_MAP_WRITE, 0, 0, sizeof(DWORD)); HANDLE caller = OpenProcess(PROCESS_DUP_HANDLE, FALSE, cwp->wParam); HANDLE current = OpenProcess(PROCESS_DUP_HANDLE | PROCESS_VM_OPERATION | PROCESS_VM_READ | PROCESS_VM_WRITE | SYNCHRONIZE, FALSE, GetCurrentProcessId()); HANDLE dup; DuplicateHandle(CurrentProcess, current, caller, &dup, 0, 0, DUPLICATE_SAME_ACCESS); InterlockedExchange(buffer, (DWORD)dup); // Cleanup handles etc. }The message parameters are the process ID of the caller, who wants to open the process handle and an incrementing counter. These parameters are used to open a named memory section to transfer the duplicated handle value back to the caller. A copy of the current process handle is then opened with a limited set of access rights and duplicated to the caller. Finally the handle value is copied into the shared memory and the message handler returns. The caller of the API can now pick up the duplicated handle and use it as desired.
This code might explain a few additional things about the API documentation. If the two processes are running as different users it’s possible that the target process won’t be able to open the caller for
PROCESS_DUP_HANDLEaccess and the transfer will fail. While the API does set the integrity level of the shared memory it doesn’t set the DACL so that will also prevent it being opened by a different user. Of course if the target process was running as an administrator, like in the UAC case, it almost certainly will have access to both the caller process as well as the shared memory making this a moot point.One minor change was made in Windows 7, the hook function was moved out of the main
oleacc.dlllibrary into its own binary,oleacchooks.dll. The hook function is exposed as ordinal 1 in the export table with no name. This DLL still exists on the latest version of Windows 11 even though the API has since moved into the kernel and there’s no longer any users.The Second Version
The second version of the API doesn’t appear until well into Windows 10’s lifetime, in version 1803. This version is where the API was moved into a Win32k kernel function. The kernel API is exposed as
NtUserGetWindowProcessHandlefromwin32kfull.sys. It’s roughly implemented as follows:HANDLE NtUserGetWindowProcessHandle(HWND hWnd, ACCESS_MASK DesiredAccess) { WND* wnd = ValidateHwnd(Wnd); if (!wnd) { return NULL; } THREADINFO* curr_thread = W32GetThreadWin32Thread(KeGetCurrentThread()); THREADINFO* win_thread = wnd->Thread;; if (curr_thread->Desktop != win_thread->Desktop) { goto access_denied; } PROCESSINFO* win_process = win_thread->ppi; PROCESSINFO* curr_process = curr_thread->ppi; if (gbEnforceUIPI) { if (!CheckAccess(curr_process->UIPIInfo, win_process->UIPIInfo)) { if (!curr_process->HasUiAccessFlag) { goto access_denied; } } } else if (win_thread->AuthId != curr_thread->AuthId) { goto access_denied; } if (win_thread->TIF_flags & (TIF_SYSTEMTHREAD | TIF_CSRSSTHREAD)) { goto access_denied; } KPROCESS process = NULL; DWORD process_id = PsGetThreadProcessId(win_thread->KThread); PsLookupProcessByProcessId(process_id, &process); HANDLE handle = NULL; ObOpenObjectByPointer(process, 0, NULL, DesiredAccess, PsProcessType, KernelMode, &handle); return handle; access_denied: UserSetLastError(ERROR_ACCESS_DENIED); return NULL; }One thing to note with the new API is it takes an
ACCESS_MASKto specify what access the caller wants on the process handle. This is different from the old implementation where the access desired was a fixed value. The window handle is validated and used to lookup the Win32kTHREADINFOstructure for the associated thread and a check is made to ensure both the caller’s thread and the target window are on the same desktop.We then get to the UIPI enforcement checks, first it checks the
gbEnforceUIPIglobal variable. If UIPI is enabled it’ll call aCheckAccessmethod to see if the caller is permitted to access the process for the target window. If the check fails it’ll test if the caller has the UI Access flag enabled, if not the function will deny access, otherwise it’ll be allowed to continue. The access check is quite simple:BOOLEAN CheckAccess(UIPI_INFO *Current, UIPI_INFO* Target) { if (Current->IntegrityLevel > Target->IntegrityLevel) { return TRUE; } if (Current->IntegrityLevel != Target->IntegrityLevel) { return FALSE; } if (Current->AppContainerNo != Target->AppContainerNo && Current->AppContainerNo != -1 && Target->AppContainerNo != -1) { return FALSE; } return TRUE: }If the caller’s integrity level is greater than the target’s, the check is passed immediately. If it’s less than the target’s then it fails immediately. However if the integrity level is the same it does a check to make sure if the processes are in an AppContainer sandbox and that they’re in the same one. If a process is not in an AppContainer sandbox the
AppContainerNovalue is set to -1. The check also ensures that this doesn’t allow a low integrity process access to an AppContainer process as there’s an existing check to prevent this happening viaOpenProcess. If everything passes the check returns TRUE.If UIPI is not enforced then the authentication IDs are compared. The function will only permit access if the caller is in the same logon session, which would mean if UIPI was disabled this wouldn’t permit accessing elevated UAC processes. The final check is whether the target thread is in the system (i.e. kernel) process or a CSRSS process. If they are then access is denied.
Finally, the target process is opened by its process ID by looking up the
KPROCESSpointer then usingObOpenObjectByPointerto open a handle with the desired access. Crucially the access mode is set toKernelMode. This means that no access checks are performed on the process object.One glaring security issue with this function is that the target process is opened without access checking for any access rights the caller wants. This is a problem as it allows any process with the same or higher integrity level to open any other process as long as it has at least one window.
This is a special problem for two process types, first is restricted token sandbox processes. While you might assume this wouldn’t be a big deal if two restricted token sandboxed processes running at the same integrity could access each other, that isn’t always the case. For example Chromium doesn’t allow renderers to open each other, and some renderers have more privilege that others for example if they’re rendering WebUI content. Fortunately at least in this case renderers run under win32k lockdown meaning they can’t create a window even if they wanted to.
The second is protected processes. If you open a handle to a protected process with the access mode set to
KernelModethen it’ll be permitted completely bypassing the protection. You might not think a protected process would create a window, but it could be a message-only window such as to support COM which the code might not even realize it created.However, even if the caller doesn’t have a suitable integrity level it’s sufficient to just have the UI Access flag enabled. This means that tricks such as my token stealing attack would be sufficient to open any other process on the same desktop which created a window. This issue was reported to MSRC and fixed as CVE-2023-41772. The reporter was the same researcher Sascha Mayer who found the Quick Assist UI Access bypass that I mentioned earlier.
The Third Version
This version’s goal was to fix CVE-2023-41772 and there are two major changes. First and most importantly, if the UIPI check fails, the function will still check for the UI Access flag being enabled. However, rather than permitting it to continue, it’ll force the call to
ObOpenObjectByPointerto open a handle with the access mode set toUserModerather thanKernelMode.Passing
UserModeensures that access checking is enabled. The end result is having the UI Access flag enabled doesn’t grant any additional privileges over calling theNtOpenProcesssystem call directly. Presumably it was left this way for compatibility reasons. However, this didn’t change the behavior when the caller’s integrity level is greater or equal to the target’s, the process object will still be opened with the access mode set toKernelMode. This means that when it comes to restricted token sandboxes or protected processes nothing has changed.The second, less important change is that the desired access is now restricted to a limited set of access rights matching the original hook based implementation. The caller can only pass the following access to the function,
PROCESS_DUP_HANDLE,PROCESS_VM_OPERATION,PROCESS_VM_READandPROCESS_VM_WRITEotherwise access is denied. However this amount of access is more than sufficient to completely compromise the target process.The Latest Version
Windows 11 24H2 introduced two major changes to the behavior of
NtUserGetWindowProcessHandle. First there is a change to the UIPI access check, let’s look at a code snippet:BOOLEAN UIPrivilegeIsolation::CheckAccess(UIPI_INFO *Current, UIPI_INFO* Target) { if (!Feature_UIPIAlwaysOn_IsEnabled() && !UIPrivilegeIsolation::fEnforceUIPI) { return TRUE; } if (Target->ProcessProtection != 0 && (Target->ProcessProtection != Current->Protection)) { return FALSE; } if (Current->IntegrityLevel > Target->IntegrityLevel) { return TRUE; } ... }The change introduces a Window feature flag to force UIPI on all the time, previously it was possible to disable UIPI using a system configuration change. A feature flag allows Microsoft to run A/B testing on Windows systems; it likely means that they want to enable UIPI permanently in the future.
The kernel driver also captures the process protection as part of the UIPI information and does a check that either the target is unprotected or the caller has a matching protection level. This stops the previous attack that allows
NtUserGetWindowProcessHandlefrom opening a protected process.One weakness in this check is it doesn’t use the comparison that the kernel uses to determine whether a protected level supersedes another. While that’s good in a way, there is a slight mistake. There’s a PPL App level that’s designed so that other processes at the same level can’t open one another. This behavior is presumably because the PPL App level was designed to be used by third party applications from the Windows Store. The implemented check would allow one PPL App process to open another, of course you’d still need to get code execution in a PPL App process to begin with so this doesn’t seem a major issue.
It’s important to note that the protection check is ignored if UIPI is disabled at a system level. Therefore if you’re willing to reboot the system and have administrator access you can disable UIPI by setting an
EnforceUIPIDWORD registry value with the value of 0 inside the keyHKLM\Software\Microsoft\Windows\CurrentVersion\Policies\System. You might also need to disable theUIPIAlwaysOnfeature flag, you can do that using a tool like ViVe and running the commandViveTool.exe /disable /id:56625134as an administrator and rebooting the machine.The second major change is in
NtUserGetWindowProcessHandle. The function now has two paths controlled by a feature flagResponsiblePid. If the feature flag is disabled it takes the old path, but if it’s enabled it calls a new functionGetWindowProcessHandleUnsafe. Ironically, contrary to the name this seems to be a safer version of the API.The big change here is that to open a process the caller must have the UI Access flag enabled. Calling the API without the UI Access flag will give an access denied error. Also if you disable UIPI at the system level the API will also return access denied, it won’t fall back to an insecure mode of operation. At least on my 25H2 VM the
ResponsiblePidfeature flag is always enabled, but I could just be subject to A/B testing.To open the process with
KernelModeaccess you’ll still need to pass the UIPI check. As you can’t short circuit the check by disabling enforcement; this blocks opening protected processes. Therefore on the latest versions of Windows 11 to access a protected process, not only do you need to disable UIPI, and theUIPIAlwaysOnfeature flag but also theResponsiblePidfeature flag to access the old implementation. TheResponsiblePidfeature flag ID is56032228if you want to disable it with ViVe. This of course requires administrator access and rebooting the machine, it might just be easier to load a kernel driver.Hijacking a TCB level Protected Process
Assuming you’re still running Windows 10 (where this will likely be a forever bug), a pre-24H2 Windows 11 (23H2 Enterprise/Education is still supported until November 2026) or have fully disabled UIPI, we can now
GetProcessHandleFromHwndto compromise a protected process.Ideally we want to get the highest level,
Protected TCBto allow us to then open any other user process on the system regardless of the protection state. How do we get a process running atProtected TCBlevel to create a window we can use to open the process handle? I’ve already described how to do this in a previous blog post back in 2018 on hijacking a protected process through the use of the COMIRundowninterface.Specifically it was possible to force
WerFaultSecure.exerunning atProtected TCBlevel to initialize a COM single-threaded apartment (STA). This allowed access to theIRundowninterface, but more importantly for our purposes a STA also sets up a message only window with theOleMainThreadWndClassclass, which is used for posting calls back to the apartment thread.However it turns out even easier if we no longer need to force COM to initialize.
WerSecureFault.exewill create a number of windows automatically during normal operation. First you need to run the process at the protected level in “upload” mode. Using the following command line:WerFaultSecure.exe -u -p {PID} -ip {PARENT_PID} -s {SECTION_HANDLE}Replace
PIDwith the process ID of a dummy process to debug,PARENT_PIDwith your current process ID andSECTION_HANDLEis a handle to a shared memory section containing the following 32 bit integers,0xF8,PIDandTIDwhere PID and TID are the process ID and thread ID of the dummy debug process. This section handle must be inherited into the new process at creation time.Next you need to find the created window, but that’s easy. Just enumerate windows using the FindWindowEx API. For each window you can lookup the PID using GetWindowThreadProcessId and match it against the created protected process.You might need to use something like an opportunistic lock to suspend the
WerFaultSecure.exeprocess after it has created the window to give you time to enumerate them.The final step is to call
GetProcessHandleFromHwndwith the found window handle and you should get a process handle back withPROCESS_DUP_HANDLE, PROCESS_VM_OPERATION, PROCESS_VM_READ, PROCESS_VM_WRITE, PROCESS_QUERY_LIMITED_INFORMATIONaccess. Typically with this access I’d duplicate a copy of the current process pseudo handle to get a full access handle. However due to the way protected processes work this will fail, as the protection checks cover both opening the process directly and duplicating the handle.Therefore, this is all the access you’re going to get. While you can’t just create a new thread in the process, it gives you sufficient access to the process to allocate and modify executable memory so a simple attack would be to write some shell code into the process and modify an existing jump to execute the code. I’ll leave the final exploitation as an exercise for the reader. Alternatively Sascha Mayer has published a PoC after I had posted a screenshot of my version’s console output that you can play with instead.
Conclusions
In conclusion the
GetProcessHandleFromHwndfunction is quite interesting in how it’s evolved over the years. The first version using windows hooks was actually secure against accessing protected processes as you can’t duplicate a process handle with access rights such asPROCESS_VM_READfrom a protected process to a non-protected process. However it was decided it’d be better to do it all in kernel mode, but the check for protected processes was forgotten.Finally in Windows 11 24H2, along with a general shake up of UIPI this seems to be fixed and the function is also no longer quite so dangerous. Time will tell if at least some of the changes, like making UIPI permanent, come to pass.
-
🔗 r/LocalLLaMA Qwen3.5 122B in 72GB VRAM (3x3090) is the best model available at this time — also it nails the “car wash test” rss
 | I am absolutely loving Qwen3.5 122B! It’s the best model I can run on my 72GB VRAM setup, fully loaded on GPU including context. Very good speed at 25 tok/s. Fiddled a bit with the settings to get it to work properly. If you are experiencing endless “but wait” loops, this is what worked for me:
| I am absolutely loving Qwen3.5 122B! It’s the best model I can run on my 72GB VRAM setup, fully loaded on GPU including context. Very good speed at 25 tok/s. Fiddled a bit with the settings to get it to work properly. If you are experiencing endless “but wait” loops, this is what worked for me:- Thinking mode on
- Temperature 0.6
- K Sampling 20
- Top P sampling 0.8
- Min P sampling 0
- Repeat penalty 1.3
Running it in Q3_K it’s a bit slower than GLM Air (30 t/s in IQ4_NL) and GPT- OSS-120B (30-38 t/s in MXFP4), but because it has a smaller footprint in Q3 I am able to push the context to 120k which is great! I tried both MXFP4 and IQ4_XS, but they are too close to 70GB when loaded, forcing me to offload 2-3 layers to RAM or context in RAM — dropping to only 6-8 tok/s. Saw on unsloth website that Q3_K_XL might actually perform on par with the 4bit ones, and I can confirm so far it’s been amazing! submitted by /u/liviuberechet
[link] [comments]
---|--- -
🔗 r/york Micklegate Bar, York’s historic western gateway✨ rss
 | @ york.england submitted by /u/WonderfulShape1081
| @ york.england submitted by /u/WonderfulShape1081
[link] [comments]
---|--- -
🔗 r/Yorkshire LiveScience: "Babies weren't supposed to be mourned in the Roman Empire; These rare liquid-gypsum burials prove otherwise" rss
 | submitted by /u/JapKumintang1991
| submitted by /u/JapKumintang1991
[link] [comments]
---|--- -
🔗 HexRaysSA/plugin-repository commits sync repo: ~1 changed rss
sync repo: ~1 changed ## Changes - [bitopt](https://github.com/teflate/bitopt): - 1.0.0: archive contents changed, download URL changed -
🔗 badlogic/pi-mono v0.55.1 release
New Features
- Added offline startup mode via
--offline(orPI_OFFLINE) to disable startup network operations, with startup network timeouts to avoid hangs in restricted or offline environments. - Added
gemini-3.1-pro-previewmodel support to thegoogle-gemini-cliprovider (#1599 by @audichuang).
Fixed
- Fixed offline startup hangs by adding offline startup behavior and network timeouts during managed tool setup (#1631 by @mcollina)
- Fixed Windows VT input initialization in ESM by loading koffi via createRequire, avoiding runtime and bundling issues in end-user environments (#1627 by @kaste)
- Fixed managed
fd/rgbootstrap on Windows in Git Bash by usingextract-zipfor.ziparchives, searching extracted layouts more robustly, and isolating extraction temp directories to avoid concurrent download races (#1348) - Fixed extension loading on Windows when resolving
@sinclair/typeboxaliases so subpath imports like@sinclair/typebox/compilerresolve correctly. - Fixed adaptive thinking for Claude Sonnet 4.6 in Anthropic and Bedrock providers, and clamped unsupported
xhigheffort values to supported levels (#1548 by @tctev) - Fixed Vertex ADC credential detection race by avoiding caching a false negative during async import initialization (#1550 by @jeremiahgaylord-web)
- Fixed subagent extension example to resolve user agents from the configured agent directory instead of hardcoded paths (#1559 by @tianshuwang)
- Added offline startup mode via
-
🔗 Console.dev newsletter Dozzle rss
Description: Container monitoring & logging.
What we like: Captures logs from Docker, k8s, Podman. Self-hosted. Set up alerts (Slack, Discord, webhooks) for search terms. Use SQL queries to analyze logs.
What we dislike: Good for self-hosted personal projects - their cloud service may be more suitable for important production environments.
-
🔗 Console.dev newsletter Rari rss
Description: React framework with Rust runtime.
What we like: Standard React, but with the HTTP server, RSC renderer, and routing handled by a v8 Rust runtime. True server-side rendering means much faster response times. Standard npm package resolution.
What we dislike: Still very early and experimental, but the performance benefits are interesting.
-
- February 25, 2026
-
🔗 IDA Plugin Updates IDA Plugin Updates on 2026-02-25 rss
IDA Plugin Updates on 2026-02-25
New Releases:
Activity:
- bitopt
- capa
- 10dfd287: ci: cache vivisect workspaces between CI runs to speed up tests (#2881)
- HappyIDA
- ida-free-mcp
- d97d78ca: Add multi-instance support, Windows/MSVC build, CI, and release workflow
- idasql
- iOS-Study
- python-elpida_core.py
- showcomments
- 20cd7dd7: Bump version
- b21e71c2: Replace old demo with screenshot
- aad22f8e: Set minimum version to 9.2
- f7bc8066: Clicking a comment also jumps to it (closes #13)
- 142d7c0c: Limit comment column to 300 by default
- 0c7be2f7: Use a columns list for easier expansion
- b8b1c702: Smaller, centered, logo
- 62e2737e: Reorganize imports
- 01424134: Update IDA JSON file
- 85b8e161: Improve README
- 85ad8a21: Suggest hcli as default installation method
- tomsons_RE_scripts
- 76cb3125: more unknown finder patterns
-
🔗 r/Harrogate Knaresborough History - Pictures you may have not seen rss
submitted by /u/No_Nose_3849
[link] [comments] -
🔗 r/Yorkshire Harrogate and Knaresborough rss
Hello hivemind.
I'm visiting Harrogate and Knaresborough for a day or two with my boyfriend soon.
What are some decent pubs and bars, and quirky or weird or artsy things to do while we're there please? Looking for recommendations of the things that a tourist can't just google, or the things that while obvious are still absolute musts!
Thanks in advance!
submitted by /u/delazouch
[link] [comments] -
🔗 MetaBrainz Picard 3 alpha 3 released rss
While our hearts are heavy following Rob’s passing, we remain committed to our mission and carry on, as Rob would have expected from us.
Today, we're making available another pre-release version for the upcoming MusicBrainz Picard 3. Alpha 3 focuses on fixing issues that were found in the previous releases as well as some minor improvements and updated translations.
Download links and a list of changes since Picard 3 alpha 2 are available below. For a more detailed overview of what is new in Picard 3 please see the previous blog post Picard 3 Alpha Release.
As before this is still an early pre-release. While we have all the major features implemented and we are rather confident in the current code, it is still a development release and it is expected there will be bugs. If you use this, do so with care, backup your files and please report any issues you encounter.
Some of the changes are also backward incompatible, hence we recommend you make a backup of your Picard.ini config file before trying the alpha version. You can do so in Picard’s Options under Advanced > Maintenance.
Thanks a lot to everyone who gave feedback, reported issues and provided translations.
What’s new?
Bugfixes
- PICARD-3191 - Crash when copying from the first column of the metadata view
- PICARD-3192 - Crash when converting configuration file
- PICARD-3195 - macOS: No Dock icon or menus
- PICARD-3196 - Persisted main view columns settings easily break if default column change
- PICARD-3197 - Fails to launch when there's a global libssl installed
- PICARD-3198 - Restore defaults on one page restores the defaults on all pages
- PICARD-3202 - Wrong disc ID calculation for SCSI TOCs that contain a trailing data track
New Features
- PICARD-2892 - Support disc ID lookup from
itunes_cddb_1tag
Improvements
- PICARD-2670 - Add filename and directory as pre-defined columns
- PICARD-3203 - Allow adding "Lookup CD log file" action to toolbar
Download
As this is a pre-release and early alpha version, it is not available on all the channels where Picard’s current stable version is available.
We appreciate your interest in trying this new version. Use with care, backup your files and please use theMetaBrainz community forums and the ticket system to give feedback and report bugs.
- MusicBrainz Picard for Windows (installer)
- MusicBrainz Picard for Windows (portable)
- MusicBrainz Picard for macOS (Intel)
- MusicBrainz Picard for macOS (ARM64)
- Source code
Picard is free software and the source code is available on GitHub.
-
🔗 skylot/jadx 1.5.5 release
Major bug fixed
- Code area was updated from wrong thread causing many exception report popups, UI freezes and high CPU usage (#2798)
Other Bug Fixes
- [gui] Resolve possible NPE during project data loading (#2794)
- [gui] Stop token process on
NULLtoken in JadxTokenMaker (#2798) - [gui] Make the Split view checkbox correctly toggle between both modes (PR #2801)
- [core] Insert generic casts for variable assigned from fields with known types (#2776)
Full Changelog :
v1.5.4...v1.5.5Download files:
- jadx-gui-1.5.5-with-jre-win.zip - jadx-gui with bundled JRE
- jadx-gui-1.5.5-win.zip - jadx-gui Windows executable (system JRE must be installed)
- jadx-1.5.5.zip - cross-platform cli and gui bundle (system JRE must be installed)
For system JRE the latest version is always preferred, download at oracle.com
-
🔗 Simon Willison I vibe coded my dream macOS presentation app rss
I gave a talk this weekend at Social Science FOO Camp in Mountain View. The event was a classic unconference format where anyone could present a talk without needing to propose it in advance. I grabbed a slot for a talk I titled "The State of LLMs, February 2026 edition", subtitle "It's all changed since November!". I vibe coded a custom macOS app for the presentation the night before.

I've written about the last twelve months of development in LLMs in December 2023, December 2024 and December 2025. I also presented The last six months in LLMs, illustrated by pelicans on bicycles at the AI Engineer World’s Fair in June 2025. This was my first time dropping the time covered to just three months, which neatly illustrates how much the space keeps accelerating and felt appropriate given the November 2025 inflection point.
(I further illustrated this acceleration by wearing a Gemini 3 sweater to the talk, which I was given a couple of weeks ago and is already out-of-date thanks to Gemini 3.1.)
I always like to have at least one gimmick in any talk I give, based on the STAR moment principle I learned at Stanford - include Something They'll Always Remember to try and help your talk stand out.
For this talk I had two gimmicks. I built the first part of the talk around coding agent assisted data analysis of Kākāpō breeding season (which meant I got to show off my mug), then did a quick tour of some new pelicans riding bicycles before ending with the reveal that the entire presentation had been presented using a new macOS app I had vibe coded in ~45 minutes the night before the talk.
Present.app
The app is called Present - literally the first name I thought of. It's built using Swift and SwiftUI and weighs in at 355KB, or 76KB compressed. Swift apps are tiny!
It may have been quick to build but the combined set of features is something I've wanted for years.
I usually use Keynote for presentations, but sometimes I like to mix things up by presenting using a sequence of web pages. I do this by loading up a browser window with a tab for each page, then clicking through those tabs in turn while I talk.
This works great, but comes with a very scary disadvantage: if the browser crashes I've just lost my entire deck!
I always have the URLs in a notes file, so I can click back to that and launch them all manually if I need to, but it's not something I'd like to deal with in the middle of a talk.
This was my starting prompt:
Build a SwiftUI app for giving presentations where every slide is a URL. The app starts as a window with a webview on the right and a UI on the left for adding, removing and reordering the sequence of URLs. Then you click Play in a menu and the app goes full screen and the left and right keys switch between URLs
That produced a plan. You can see the transcript that implemented that plan here.
In Present a talk is an ordered sequence of URLs, with a sidebar UI for adding, removing and reordering those URLs. That's the entirety of the editing experience.
When you select the "Play" option in the menu (or hit Cmd+Shift+P) the app switches to full screen mode. Left and right arrow keys navigate back and forth, and you can bump the font size up and down or scroll the page if you need to. Hit Escape when you're done.
Crucially, Present saves your URLs automatically any time you make a change. If the app crashes you can start it back up again and restore your presentation state.
You can also save presentations as a
.txtfile (literally a newline-delimited sequence of URLs) and load them back up again later.Remote controlled via my phone
Getting the initial app working took so little time that I decided to get more ambitious.
It's neat having a remote control for a presentation...
So I prompted:
Add a web server which listens on 0.0.0.0:9123 - the web server serves a single mobile-friendly page with prominent left and right buttons - clicking those buttons switches the slide left and right - there is also a button to start presentation mode or stop depending on the mode it is in.
I have Tailscale on my laptop and my phone, which means I don't have to worry about Wi-Fi networks blocking access between the two devices. My phone can access
http://100.122.231.116:9123/directly from anywhere in the world and control the presentation running on my laptop.It took a few more iterative prompts to get to the final interface, which looked like this:
There's a slide indicator at the top, prev and next buttons, a nice big "Start" button and buttons for adjusting the font size.
The most complex feature is that thin bar next to the start button. That's a touch-enabled scroll bar - you can slide your finger up and down on it to scroll the currently visible web page up and down on the screen.
It's very clunky but it works just well enough to solve the problem of a page loading with most interesting content below the fold.
Learning from the code
I'd already pushed the code to GitHub (with a big "This app was vibe coded [...] I make no promises other than it worked on my machine!" disclaimer) when I realized I should probably take a look at the code.
I used this as an opportunity to document a recent pattern I've been using: asking the model to present a linear walkthrough of the entire codebase. Here's the resulting Linear walkthroughs pattern in my ongoing Agentic Engineering Patterns guide, including the prompt I used.
The resulting walkthrough document is genuinely useful. It turns out Claude Code decided to implement the web server for the remote control feature using socket programming without a library! Here's the minimal HTTP parser it used for routing:
private func route(_ raw: String) -> String { let firstLine = raw.components(separatedBy: "\r\n").first ?? "" let parts = firstLine.split(separator: " ") let path = parts.count >= 2 ? String(parts[1]) : "/" switch path { case "/next": state?.goToNext() return jsonResponse("ok") case "/prev": state?.goToPrevious() return jsonResponse("ok")
Using GET requests for state changes like that opens up some fun CSRF vulnerabilities. For this particular application I don't really care.
Expanding our horizons
Vibe coding stories like this are ten a penny these days. I think this one is worth sharing for a few reasons:
- Swift, a language I don't know, was absolutely the right choice here. I wanted a full screen app that embedded web content and could be controlled over the network. Swift had everything I needed.
- When I finally did look at the code it was simple, straightforward and did exactly what I needed and not an inch more.
- This solved a real problem for me. I've always wanted a good way to serve a presentation as a sequence of pages, and now I have exactly that.
- I didn't have to open Xcode even once!
This doesn't mean native Mac developers are obsolete. I still used a whole bunch of my own accumulated technical knowledge (and the fact that I'd already installed Xcode and the like) to get this result, and someone who knew what they were doing could have built a far better solution in the same amount of time.
It's a neat illustration of how those of us with software engineering experience can expand our horizons in fun and interesting directions. I'm no longer afraid of Swift! Next time I need a small, personal macOS app I know that it's achievable with our existing set of tools.
You are only seeing the long-form articles from my blog. Subscribe to /atom/everything/ to get all of my posts, or take a look at my other subscription options.
-
🔗 r/Yorkshire Bridlington or Cleethorpes rss
I am fed up where I live. I would love to move and I would like a flat. I have practically paid off my mortgage so I could get mortgage free paying cash. I would like somewhere like Cleethorpes or Brid? Or any other suggestions welcome
submitted by /u/Weird_Fun1493
[link] [comments] -
🔗 r/LocalLLaMA Qwen 3.5 craters on hard coding tasks — tested all Qwen3.5 models (And Codex 5.3) on 70 real repos so you don't have to. rss
 | Hey everyone, some of you might remember https://www.reddit.com/r/LocalLLaMA/comments/1r7shtv/i_built_a_benchmark_that_tests_coding_llms_on/ where I shared APEX Testing — my benchmark that tests coding models on real codebases with real problems. Since then I've added 5 more tasks (now 70 total), and more importantly tested a bunch of new models people were asking about: all the Qwen 3.5 variants, GPT-5.3 Codex, and several local quantized models running on LM Studio. I also built a proper agentic tool-use system for the local models now — instead of dumping the entire repo into one prompt, models get all required tools and they explore + implement on their own, just like the cloud agentic models do. Way fairer comparison. Heavy anti-benchmaxxing focus is in place as well so GL to companies who try to take that approach and promise the moon and the stars :) What caught me off guard: - Codex 5.3 is basically tied with GPT-5.2 at #4 overall. barely drops across difficulty levels — super consistent from easy to master tasks -> Recommended - Qwen 3.5 397B craters on master tasks. holds ~1550 ELO on hard/expert which is respectable, but drops to 1194 on master. when it needs to coordinate across many files over many steps, it just loses track of what it's doing - GLM-4.7 quantized is still the local GOAT. 1572 ELO, beats every single Qwen 3.5 model including the full 397B cloud version. if you're picking one local model for coding, this is still it (better than GLM-5 even!) - Qwen 3.5 27B is genuinely decent on a single GPU though. 1384 ELO, beats DeepSeek V3.2 and all the qwen3-coder models. for "fix this bug" / "add this endpoint" type work it holds up - The 35B MoE (3B active) is rough. 1256, worse than the 27B dense on almost everything. the tiny active param count really shows on multi-step agentic work - One qwen model found a loophole lol — qwen3.5-27b ran the test suite on a master task, saw existing tests passing, declared everything "already implemented" and quit without writing a single line of code. it was the only model out of 25+ that tried this. had to patch my system after that one 😅 Still running: Qwen 3.5 122B only has 3/70 tasks done so take that ranking with a grain of salt. Also planning BF16 and Q8_K_XL runs for the Qwen3.5 models to show the real quantization tax — should have those up in a day or two. Methodology in brief: 70 tasks across real GitHub repos — bug fixes, refactors, from-scratch builds, debugging race conditions, building CLI tools, you name it. All models get the same starting point, agentic tool-use, scored on Correctness/completeness/quality/efficiency, ELO calculated pairwise with difficulty adjustments. task titles are public on the site, prompts/diffs kept private to avoid contamination. solo project, self-funded ($3000 and counting lol). Full leaderboard with filters by category, difficulty, per-model breakdowns, and individual run data: https://www.apex-testing.org Happy to answer questions, and if you want a specific model tested let me know and I might add it! EDIT: Currently recalculating and migrating the DB - results will be fully up and updated within 24h (writing this as of midnight CET 27th Feb) submitted by /u/hauhau901
| Hey everyone, some of you might remember https://www.reddit.com/r/LocalLLaMA/comments/1r7shtv/i_built_a_benchmark_that_tests_coding_llms_on/ where I shared APEX Testing — my benchmark that tests coding models on real codebases with real problems. Since then I've added 5 more tasks (now 70 total), and more importantly tested a bunch of new models people were asking about: all the Qwen 3.5 variants, GPT-5.3 Codex, and several local quantized models running on LM Studio. I also built a proper agentic tool-use system for the local models now — instead of dumping the entire repo into one prompt, models get all required tools and they explore + implement on their own, just like the cloud agentic models do. Way fairer comparison. Heavy anti-benchmaxxing focus is in place as well so GL to companies who try to take that approach and promise the moon and the stars :) What caught me off guard: - Codex 5.3 is basically tied with GPT-5.2 at #4 overall. barely drops across difficulty levels — super consistent from easy to master tasks -> Recommended - Qwen 3.5 397B craters on master tasks. holds ~1550 ELO on hard/expert which is respectable, but drops to 1194 on master. when it needs to coordinate across many files over many steps, it just loses track of what it's doing - GLM-4.7 quantized is still the local GOAT. 1572 ELO, beats every single Qwen 3.5 model including the full 397B cloud version. if you're picking one local model for coding, this is still it (better than GLM-5 even!) - Qwen 3.5 27B is genuinely decent on a single GPU though. 1384 ELO, beats DeepSeek V3.2 and all the qwen3-coder models. for "fix this bug" / "add this endpoint" type work it holds up - The 35B MoE (3B active) is rough. 1256, worse than the 27B dense on almost everything. the tiny active param count really shows on multi-step agentic work - One qwen model found a loophole lol — qwen3.5-27b ran the test suite on a master task, saw existing tests passing, declared everything "already implemented" and quit without writing a single line of code. it was the only model out of 25+ that tried this. had to patch my system after that one 😅 Still running: Qwen 3.5 122B only has 3/70 tasks done so take that ranking with a grain of salt. Also planning BF16 and Q8_K_XL runs for the Qwen3.5 models to show the real quantization tax — should have those up in a day or two. Methodology in brief: 70 tasks across real GitHub repos — bug fixes, refactors, from-scratch builds, debugging race conditions, building CLI tools, you name it. All models get the same starting point, agentic tool-use, scored on Correctness/completeness/quality/efficiency, ELO calculated pairwise with difficulty adjustments. task titles are public on the site, prompts/diffs kept private to avoid contamination. solo project, self-funded ($3000 and counting lol). Full leaderboard with filters by category, difficulty, per-model breakdowns, and individual run data: https://www.apex-testing.org Happy to answer questions, and if you want a specific model tested let me know and I might add it! EDIT: Currently recalculating and migrating the DB - results will be fully up and updated within 24h (writing this as of midnight CET 27th Feb) submitted by /u/hauhau901
[link] [comments]
---|--- -
🔗 r/Yorkshire Recommend me your favourite affordable place to live! rss
I'm helping a family member look for a new place to live in the UK due to a sudden change in circumstances. Their budget is 200-300k. Ideally somewhere northern.
They are retired, would like to maximize on space and have a garden. Ideally village/small town (I would love them to have a few walkable amenities but that's not necessary for them). They are getting older so somewhere safe is most important, and they are very used to quiet village life.
Where would you recommend? They/we have lived in the same bubble for the last 25 years, so I'm looking to expand horizons and look at places that may not have been considered.
Trying to help them out of a stressful situation so any help or advice is appreciated.
Edit: thanks all for your responses. I will look into these options.
submitted by /u/Sad-Asparagus275
[link] [comments] -
🔗 r/wiesbaden Damenfriseur für lockige Haare (3C) rss
Hallo zusammen,
meine Frau sucht im Rhein-Main-Gebiet einen guten und nicht so teuren Friseur für ihre lockigen Haare (Typ 3C). Alle Empfehlungen bisher gingen so Richtung 200€. Ich habe gesagt, auf Reddit gibt es bestimmt jemand, der noch weitere kennt. Habe einmal ihre Nachricht eingefügt und hoffe, ihr kennt jemanden. Vielen Dank ☺️
"Hallo ihr Lieben! 😊
Ich suche einen guten Friseursalon oder einen Friseurin, der/die sich mit lockigen Haaren auskennt.
Ich habe Haartyp 3C und hätte total Lust auf einen neuen Look ✂️✨
Habt ihr Empfehlungen?
Vielen lieben Dank schon mal!"
submitted by /u/nate23x
[link] [comments] -
🔗 r/york Jobs with no experience needed rss
Hi, my (23M) girlfriend (23F) has been looking for jobs in York on Indeed and in person. Applied for countless jobs in York, Leeds and Harrogate since September and hasn't yet gotten anything, seldom gets an interview. It's getting so tiring and so demoralising. She dropped out of uni in Sheffield due to mental health and ADHD/Autism.
I'm trying to support her as much as I can but I'm struggling to remain positive for her at this point because so many places either aren't suitable for her (can't drive, not suited to loud social environments like pubs/restaurants etc) or just flat out reject her without any feedback.
So, on her behalf, I'm asking for any advice, help or suggestions the good people of York can provide us with. Thank you :)
submitted by /u/WILLDABEAST145
[link] [comments] -
🔗 HexRaysSA/plugin-repository commits sync repo: +1 plugin, +1 release rss
sync repo: +1 plugin, +1 release ## New plugins - [showcomments](https://github.com/merces/showcomments) (0.6.0) -
🔗 r/reverseengineering ghidra-mcp v3.0.0 - 179 MCP tools for AI-powered reverse engineering (full headless, Ghidra Server) rss
submitted by /u/XerzesX
[link] [comments] -
🔗 r/york Made a simple site to compare fuel prices in York rss
 | I made a simple tool that shows the cheapest petrol/diesel near you: York Fuel Prices The whole point is to make it quick to compare nearby stations before you fill up. Even a 5p/L difference is about £2.50 on a 50L fill (10p/L is ~£5), so it adds up over time. It also feels timely with the UK’s Fuel Finder rollout just launched — petrol stations are now publishing prices digitally, so tools like this should get more useful as coverage improves. I know there are other apps/sites, but I wanted something that’s:
| I made a simple tool that shows the cheapest petrol/diesel near you: York Fuel Prices The whole point is to make it quick to compare nearby stations before you fill up. Even a 5p/L difference is about £2.50 on a 50L fill (10p/L is ~£5), so it adds up over time. It also feels timely with the UK’s Fuel Finder rollout just launched — petrol stations are now publishing prices digitally, so tools like this should get more useful as coverage improves. I know there are other apps/sites, but I wanted something that’s:- fast on mobile
- no account / no personal details
- less clutter
Built by one person evenings/weekends — any feedback is appreciated. Otherwise, hope it helps you save some money https://preview.redd.it/duyggcxuxmlg1.png?width=2634&format=png&auto=webp&s=a0caaf29fc9802e90b59d89e2279a1f70fce51ef submitted by /u/Used-Call-3503
[link] [comments]
---|--- -
🔗 Evan Schwartz Great RSS Feeds That Are Too Noisy to Read Manually rss
Some RSS feeds are fantastic but far too noisy to add to most RSS readers directly. Without serious filtering, you'd get swamped with more posts than you could possibly read, while missing the hidden gems.
I built Scour specifically because I wanted to find the great articles I was missing in noisy feeds like these, without feeling like I was drowning in unread posts. If you want to try it, you can add all of these sources in one click. But these feeds are worth knowing about regardless of what reader you use.
Hacker News Newest
Feed: https://hnrss.org/newest
Thousands of posts are submitted to Hacker News each week. While the front page gives a sense of what matches the tech zeitgeist, there are plenty of interesting posts that get buried simply because of the randomness of who happens to be reading the Newest page and voting in the ~20 minutes after posts are submitted. (You can try searching posts that were submitted but never made the front page in this demo I built into the Scour docs.)
Pinboard Recent
Pinboard describes itself as "Social Bookmarking for Introverts". The recent page is a delightfully random collection of everything one of the 30,000+ users has bookmarked. Human curated, without curation actually being the goal.
Bearblog Most Recent
Bear is "A privacy-first, no-nonsense, super-fast blogging platform". This post is published on it, and I'm a big fan. The Discovery feed gives a snapshot of blogs that users have upvoted on the platform. But, even better than that, the Most Recent feed gives you every post published on it. There are lots of great articles, and plenty of blogs that are just getting started.
Feedle All
Feed: https://feedle.world/rss
Feedle is a search engine for blogs and podcasts. You can search for words or phrases among their curated collection of blogs, and every search can become an RSS feed. An empty search will give you a feed of every post published by any one of their blogs.
Kagi Small Web
Kagi, the search engine, maintains an open source list of around 30,000 "small web" websites that are personal and non-commercial sites. Their Small Web browser lets you browse random posts one at a time. The RSS feed gives you every post published by any one of those websites.
Thread Reader
Thread Reader is a Twitter/X bot that lets users "unroll" threads into an easier-to-read format. While getting RSS feeds out of Twitter/X content is notoriously difficult, Thread Reader provides an RSS feed of all threads that users have used them to unroll. Like the content on that platform, the threads are very hit-or-miss, but there are some gems in there.
Minifeed Global
Not an RSS feed: https://minifeed.net/global
Minifeed is a nice "curated blog reader and search engine". They have a Global page that shows every post published by one of the blogs they've indexed. While this isn't technically an RSS feed, I thought it deserved a mention.
Note that Scour can add some websites that don't have RSS feeds. It treats pages with repeated structures that look like blogs (e.g. they have links, titles, and publish dates) as if they were RSS feeds. Minifeed's Global view is one such page, so you can also get every post published from any one of their collected blogs.
arXiv
Feeds galore: https://info.arxiv.org/help/rss.html
arXiv has preprint academic articles for technical fields ranging from Computer Science and Mathematics to Physics and Quantitative Biology. Like many of the feeds listed above, most of the categories are very noisy. But, if you're into reading academic articles, there is also plenty of great new research hidden in the noise. Every field and sub-field has its own RSS feed. (You can browse them and subscribe on Scour here).
While reading my Scour feed, I'll often check which feeds an article I liked came from (see what this looks like here), and I'm especially delighted when it comes from some source I had no idea existed.
These types of noisy feeds are great ways of discovering new content and new blogs, but you definitely need some good filters to make use of them. I hope you'll give Scour a try!
P.S. Scour makes all of the feeds it creates consumable as RSS/Atom/JSON feeds, so you can add your personalized feed or each of your interests-specific feeds to your favorite feed reader. Read more in this guide for RSS users.
-
🔗 r/Leeds Study space rss
I’m looking for a study space where I can just sit and do work without the pressure of buying a coffee/food.
I love Left Bank for this but is there any other good spaces around Leeds/Headingley?
Thank you
submitted by /u/jodans
[link] [comments] -
🔗 r/Harrogate Scotton - Experience with cell networks/broadband? rss
Currently looking to relocate to Scotton, but having some difficulty figuring out what to do with broadband and cellular networks.
The EE network is pretty poor there from what I could gather on my last visit (patchy service and 4G struggling to load directions on Google Maps on Havikil Lane and outside the pub). I’m happy to switch networks if there is one that works well. Any recommendations?
Broadband seems to be standard BT copper lines to the properties with 70mbps being the max speed (not sufficient for the working that I do from home). I am aware of a company named Quickline that will install a fibre-to-the-property line and can provide 1gbps speeds, but not sure on quality of service as I’ve not heard of them before. Any experience with them?
Any info would be greatly appreciated.
submitted by /u/GLAC13R
[link] [comments] -
🔗 r/LocalLLaMA Qwen3.5 27B better than 35B-A3B? rss
 | Which model would be better with 16 GB of VRAM and 32 GB of RAM? submitted by /u/-OpenSourcer
| Which model would be better with 16 GB of VRAM and 32 GB of RAM? submitted by /u/-OpenSourcer
[link] [comments]
---|--- -
🔗 r/LocalLLaMA Anthropic is the leading contributor to open weight models rss
It just happens to be entirely against their will and TOS. I say: Distill Baby Distill!
submitted by /u/DealingWithIt202s
[link] [comments] -
🔗 r/york first tattoo done by claudee_tattoo in york, england :) rss
submitted by /u/aster0idzz
[link] [comments] -
🔗 r/reverseengineering My first dive into reverse engineering, an open source tool to control the Zuoya GMK87 preferences and upload images to it from any OS rss
submitted by /u/codedgar
[link] [comments] -
🔗 r/LocalLLaMA Qwen3.5-35B-A3B is a gamechanger for agentic coding. rss
 | Qwen3.5-35B-A3B with Opencode Just tested this badboy with Opencode cause frankly I couldn't believe those benchmarks. Running it on a single RTX 3090 on a headless Linux box. Freshly compiled Llama.cpp and those are my settings after some tweaking, still not fully tuned: ./llama.cpp/llama-server \ -m /models/Qwen3.5-35B-A3B-MXFP4_MOE.gguf \ -a "DrQwen" \ -c 131072 \ -ngl all \ -ctk q8_0 \ -ctv q8_0 \ -sm none \ -mg 0 \ -np 1 \ -fa on Around 22 gigs of vram used. Now the fun part:
| Qwen3.5-35B-A3B with Opencode Just tested this badboy with Opencode cause frankly I couldn't believe those benchmarks. Running it on a single RTX 3090 on a headless Linux box. Freshly compiled Llama.cpp and those are my settings after some tweaking, still not fully tuned: ./llama.cpp/llama-server \ -m /models/Qwen3.5-35B-A3B-MXFP4_MOE.gguf \ -a "DrQwen" \ -c 131072 \ -ngl all \ -ctk q8_0 \ -ctv q8_0 \ -sm none \ -mg 0 \ -np 1 \ -fa on Around 22 gigs of vram used. Now the fun part:- I'm getting over 100t/s on it
- This is the first open weights model I was able to utilise on my home hardware to successfully complete my own "coding test" I used for years for recruitment (mid lvl mobile dev, around 5h to complete "pre AI" ;)). It did it in around 10 minutes, strong pass. First agentic tool that I was able to "crack" it with was Kodu.AI with some early sonnet roughly 14 months ago.
- For fun I wanted to recreate this dashboard OpenAI used during Cursor demo last summer, I did a recreation of it with Claude Code back then and posted it on Reddit: https://www.reddit.com/r/ClaudeAI/comments/1mk7plb/just_recreated_that_gpt5_cursor_demo_in_claude/ So... Qwen3.5 was able to do it in around 5 minutes.
I think we got something special here... submitted by /u/jslominski
[link] [comments]
---|--- -
🔗 matklad Against Query Based Compilers rss
Against Query Based Compilers
Feb 25, 2026
Query based compilers are all the rage these days, so it feels only appropriate to chart some treacherous shoals in those waters.
A query-based compiler is a straightforward application of the idea of incremental computations to, you guessed it, compiling. A compiler is just a simple text transformation program, implemented as a lot of functions. You could visualize a run of a compiler on a particular input source code as a graph of function calls:

Here, schematically, squares are inputs like file text or compiler’s command line arguments,
gis an intermediate function (e.g, type checking), which is called twice, with different arguments, andfandhare top-level functions (compile executable, or compute completions for LSP).Looking at this picture, it’s obvious how to make our compiler “incremental” — if an input changes, it’s enough to re-compute only the results on path from the changed input to the root “query”:

A little more thinking, and you can derive “early cutoff” optimization:

If an input to the function changes, but its result doesn’t (e.g, function type is not affected by whitespace change), you can stop change propagation early.
And that’s … basically it. The beauty of the scheme is its silvery-bullety hue — it can be applied without thinking to any computation, and, with a touch of meta programming, you won’t even have to change code of the compiler significantly.
Build Systems à la Carte is the canonical paper to read here. In a build system, a query is an opaque process whose inputs and outputs are file. In a query-based compiler, queries are just functions.
The reason why we want this in the first place is incremental compilation — in IDE context specifically, the compiler needs to react to a stream of tiny edits, and its time budget is about 100ms. Big-O thinking is useful here: the time to react to the change should be proportional to the size of the change, and not the overall size of the codebase. O(1) change leads to O(1) update of the O(N) codebase.
Similar big-O thinking also demonstrates the principal limitation of the scheme — the update work can’t be smaller than the change in the result.
An example. Suppose our “compiler” makes a phrase upper-case:
compile("hello world") == "HELLO WORLD"This is easy to incrementalize, as changing a few letters in the input changes only a few letters in the output:
compile("hallo world") == "HALLO WORLD"But suppose now our “compiler” is a hashing or encryption function:
compile("hello world") == "a948904f2f0" compile("hallo world") == "a7336983eca"This is provably impossible to make usefully incremental. The encryption can be implemented as a graph of function calls, and you can apply the general incremental recipe to it. It just won’t be very fast.
The reason for that is the avalanche property — for good encryption, a change in any bit of input should flip roughly half of the bits of the output. So just the work of changing the output (completely ignoring the work to compute what needs to be changed) is O(N), not O(1).
The effectiveness of query-based compiler is limited by the dependency structure of the source language.
A particularly nasty effect here is that even if you have only potential avalanche, where a certain kind of change could affect large fraction of the output, even if it usually doesn’t, your incremental engine likely will spend some CPU time or memory to confirm the absence of dependency.
In my
Three Architectures For Responsive IDE, query-based compilation is presented as a third, fall-back option. I still think that that’s basically true: as a language designer, I think it’s worth listening to your inner Grug and push the need for queries as far down the compilation pipeline as possible, sticking to more direct approaches. Not doing queries is simpler, faster, and simpler to make faster (profiling a query-based compiler is a special genre of hurdle racing).
Zig and Rust provide for a nice comparison. In Zig, every file can be parsed completely in isolation, so compilation starts by parsing all files independently and in parallel. Because in Zig every name needs to be explicitly declared (there’s no
use *), name resolution also can run on a per-file basis, without queries. Zig goes even further, and directly converts untyped AST into IR, emitting a whole bunch of errors in the process (e.g, “vardoesn’t need to be mutable”). See Zig AstGen: AST = > ZIR for details. By the time compiler gets to tracked queries, the data it has to work with is already pretty far from the raw source code, but only because Zig language is carefully designed to allow this.In contrast, you can’t really parse a file in Rust. Rust macros generate new source code, so parsing can’t be finished until all the macros are expanded. Expanding macros requires name resolution, which, in Rust, is a crate-wide, rather than a file-wide operation. Its a fundamental property of the language that typing something in
a.rscan change parsing results forb.rs, and that forces fine-grained dependency tracking and invalidation to the very beginning of the front-end.Similarly, the nature of the trait system is such that
implblocks relevant to a particular method call can be found almost anywhere. For every trait method call, you get a dependency on theimplblock that supplies the implementation, but you also get a dependency on non-existence of conflictingimpls in every other file!Again, refer to the Three Architectures for positive ideas, but the general trick is to leverage language semantics to manually cut the compilation tasks into somewhat coarse-grained chunks which are independent by definition (of the source language). Grug builds an incremental map-reduce compiler for his language:
-
Recursive directory walk finds all files to be compiled.
-
In parallel, independently, each file is parsed, name-resolved, and lowered. As much as possible, language features (and errors) are syntax driven and not type driven, and can be processed at this stage.
-
In parallel, a “summary” is extracted from each file, which is essentially just a list of types and signatures, with function bodies empty.
-
Sequentially, a “signature evaluation” phase is run on this set of summaries, which turns type references in signatures into actual types, dealing with mutual dependencies between files. This phase is re-run whenever a summary of a file changes. Conversely, changes to the body of any function do not invalidate resolved signatures.
-
In parallel, every function’s body is type-checked, and lowered to type-and-layout resolved IR, applying function-local optimizations.
-
Sequentially, a thin-lto style set of analyses are run on compiled functions, making inlining decisions and computing call-graph dependent attributes like function purity.
-
In parallel, each function is codegened to machine code with unresolved references to other functions (relocations).
-
Sequentially, functions are concatenated into an executable file, receiving an address.
-
In parallel, all relocations are resolved to now known addresses.
The above scheme works only if the language has a property that changing the body of function
foo(not touching its signature) can’t introduce type errors into an unrelated functionbar.
Another trick that becomes less available if you blindly apply queries are in- place updates. Consider a language with package declarations and fully qualified names, like Kotlin:
package org.example fun printMessage() { /*...*/ } class Message { /*...*/ }A compiler for this language probably wants to maintain a map of all public declarations, where the keys are fully qualified names, and values are declarations themselves. If you approach the problem of computing this map with query eyes, you might have a base per-file query that returns a map of file’s declarations, and then a recursive per-directory query. And you’ll probably have some kind of structural sharing of the maps, such that changing a single file updates only the “spine”, without actually copying most of the other entries.
But there’s a more direct way to make this sort of structure responsive to changes. You need only two “queries” — per file, and global. When a file changes, you look at the previous version of the map for this file, compute a diff of added or removed declarations, and then apply this diff to the global map.
Zig is planning to use a similar approach to incrementalize linking — rather than producing a new binary gluing mostly unchanged chunks of machine code, the idea is to in-place patch the previous binary.
If you like this article, you might be interested in some other adjacent stuff I’ve written over the years, roughly in the order of importance:
-
-
- February 24, 2026
-
🔗 IDA Plugin Updates IDA Plugin Updates on 2026-02-24 rss
IDA Plugin Updates on 2026-02-24
New Releases:
Activity:
- capa
- e9b33113: binja: add mypy config for top-level binaryninja module (#2877)
- hcon2026hwctf
- d3b84a26: ctf end
- hrtng
- ida-hcli
- c1873db7: Merge pull request #164 from HexRaysSA/fix/style-cleanup
- IDA-MCP
- 1631de2e: Merge pull request #9 from X-Cicada/docs/chinese-readme
- e2c803fe: Merge pull request #8 from X-Cicada/feature/custom-timeout
- b5d3f526: Merge pull request #7 from X-Cicada/feature/py-eval
- 4cc72832: Merge pull request #6 from X-Cicada/fix/concurrent-session
- 9ecfed10: Merge pull request #5 from X-Cicada/feature/string-cache
- playlist
- 0d6237c4: itty bitty city pop
- python-elpida_core.py
- quokka
- 9563059c: Merge pull request #91 from quarkslab/dependabot/github_actions/actio…
- capa
-
🔗 badlogic/pi-mono v0.55.0 release
Breaking Changes
- Resource precedence for extensions, skills, prompts, themes, and slash-command name collisions is now project-first (
cwd/.pi) before user-global (~/.pi/agent). If you relied on global resources overriding project resources with the same names, rename or reorder your resources. - Extension registration conflicts no longer unload the entire later extension. All extensions stay loaded, and conflicting command/tool/flag names are resolved by first registration in load order.
- Resource precedence for extensions, skills, prompts, themes, and slash-command name collisions is now project-first (
-
🔗 r/reverseengineering How to extract the firmware and convert the binary to ELF on a ESP32-PICO based water sensor device. rss
submitted by /u/Ancient-Winter5861
[link] [comments] -
🔗 @HexRaysSA@infosec.exchange 🔦 IDA Plugin Spotlight: DBImporter mastodon
🔦 IDA Plugin Spotlight: DBImporter
Import your databases from Ghidra into IDA with this new plugin. It also can be used programmatically as a Python module or a CLI tool; making headless operation and automated conversions possible.Check it out: https://hex-rays.com/blog/plugin-spotlight- dbimporter
-
🔗 r/wiesbaden Zuckerrohrsaft rss
Hallo Gemeinde, gibt es in Wiesbaden irgend einen Laden der frisch gepressten Zuckerrohrsaft verkauft? Hab ihn letztes Jahr in Ägypten getrunken und würde mich sehr freuen auch hier welchen zu finden.
submitted by /u/Weak-Cupcake9892
[link] [comments] -
🔗 r/Yorkshire Houses near pinderfield hospital rss
What are your thoughts on this area?
Houses look nice but the crime stats look high, i’m thinking the hospital itself and it’s reporting is the reason it seems so high?
Is the area good enough to raise a family?
thank you
submitted by /u/amala97
[link] [comments] -
🔗 r/Yorkshire Drax tells UK workers up to 150 jobs are at risk rss
submitted by /u/Kagedeah
[link] [comments] -
🔗 Hex-Rays Blog DBImporter: Bringing data from external RE tools into IDA rss

Transitioning between tools, whether it’s preserving the work you’ve already done or adapting to a different workflow, can be challenging at first. Here at Hex-Rays we want to make that transition easier by introducing a new plugin to our toolset: DBImporter.

-
🔗 News Minimalist 🐢 First UK baby from deceased donor womb + 10 more stories rss
In the last 4 days ChatGPT read 120455 top news stories. After removing previously covered events, there are 11 articles with a significance score over 5.5.

[6.4] First UK baby born from deceased donor womb transplant —bbc.co.uk(+15)
A baby boy has become the first child in the UK born using a womb transplanted from a deceased donor, a breakthrough for women born without viable wombs.
Grace Bell, who has MRKH syndrome, received the organ in 2024 before undergoing IVF. This milestone, part of a clinical research trial, follows the 2025 birth of a baby via a living donor transplant and offers hope to thousands of similar patients.
The transplanted womb will eventually be removed to prevent Bell from requiring lifelong immunosuppressants. Globally, over 70 babies have been born following womb transplants, though deceased donor successes remain rare in Europe.
[5.6] US Peace Corps sends AI experts abroad to boost global influence —engadget.com(+2)
The Peace Corps is launching Tech Corps, a new initiative recruiting artificial intelligence experts to serve in foreign countries to strengthen United States leadership in the global AI market.
Recruited STEM graduates will fulfill 12- to 27-month assignments in nations participating in the American AI Exports Program. These volunteers will utilize AI technology to address local challenges in critical sectors including healthcare, education, agriculture, and general economic development.
[5.6] Perseverance rover gains precise self-location capability on Mars —space.com(+4)
NASA has updated the Perseverance rover to autonomously determine its precise location on Mars using new software, eliminating Earth-based guidance and enabling faster, more extensive exploration of the planet.
The Mars Global Localization system matches panoramic imagery to orbital maps, identifying coordinates within roughly ten inches. Previously, cumulative sensor errors required mission teams on Earth to manually verify positions, a process delayed by the massive communication distance and time between the two planets.
This technology follows recent tests of AI-planned routes and digital twin simulations. Officials believe this advancement will facilitate more efficient autonomous exploration for future robotic missions on Mars and other celestial bodies.
Highly covered news with significance over 5.5
[6.5] Zimbabwe introduces twice-yearly HIV prevention injection for high-risk groups — abcnews.com (+6)
[6.3] Brazil and India forge new deal on critical minerals and rare earths — apnews.com (+13)
[5.6] Meta secures $60 billion AI chip deal with AMD — theguardian.com (+17)
[5.6] EU approves deporting asylum seekers to third countries — dw.com (Russian) (+2)
[5.6] ASML boosts high-end chip production capacity by 50% with advanced EUV lithography — valor.globo.com (Portuguese) (+6)
[5.5] China restricts exports to 40 Japanese companies over military ties — japantimes.co.jp (+14)
[5.5] Australia receives world's most powerful fully electric locomotives — farodevigo.es (Spanish) (+7)
[5.9] Netherlands appoints first openly gay prime minister — nos.nl (Dutch) (+29)
Thanks for reading!
— Vadim
You can create your own significance-based RSS feed with premium.
-
🔗 r/Leeds Manchester -> Leeds rss
Debating making the move to Leeds from Manchester, specifically Leeds City Centre for easy access to trains and a social life.
What are the pros and cons of living in Leeds City Centre? 😅
submitted by /u/kayscakes
[link] [comments] -
🔗 r/york I'm holding a workshop - does anyone know any good social media groups to promote myself on? rss
Hello!
I'm holding a Mother's Day bouquet making workshop on Sat 14th March, and I would like some advice from anyone who has held workshops in York before - what are some of the best social media pages to promote on?
I'm looking to promote to groups on Facebook, Insta etc.; would Facebook group pages like Things to do in York be helpful?
If you've run workshops before what's been the most helpful in getting your stuff out there?
I'm a small business starting up, so any advice would be much appreciated!
submitted by /u/peachranunculus
[link] [comments] -
🔗 r/Leeds Eggs in Leeds rss
Does anyone sell eggs locally in leeds, who has completely free range chickens, animal welfare is really high priority?
submitted by /u/SuccessfulBowl5152
[link] [comments] -
🔗 HexRaysSA/plugin-repository commits sync repo: ~1 changed rss
sync repo: ~1 changed ## Changes - [hrtng](https://github.com/KasperskyLab/hrtng): - 3.8.88: archive contents changed -
🔗 r/reverseengineering ROP the ROM: Exploiting a Stack Buffer Overflow on STM32H5 in Multiple Ways rss
submitted by /u/gquere
[link] [comments] -
🔗 r/Harrogate Knaresborough Leisure Hub - Your opinions? rss
submitted by /u/No_Nose_3849
[link] [comments] -
🔗 r/LocalLLaMA Qwen/Qwen3.5-122B-A10B · Hugging Face rss
 | submitted by /u/coder543
| submitted by /u/coder543
[link] [comments]
---|--- -
🔗 r/LocalLLaMA Qwen/Qwen3.5-35B-A3B · Hugging Face rss
 | submitted by /u/ekojsalim
| submitted by /u/ekojsalim
[link] [comments]
---|--- -
🔗 sacha chua :: living an awesome life La semaine du 16 février au 22 février rss
lundi 16 février
C'était le Jour de la famille, donc ma fille n'a pas eu école. Nous avons préparé des petits pains chinois au porc char siu. Cette fois, j'ai encore utilisé la recette pour les petits pains à la vapeur, mais j'ai laissé la pâte reposer plus longtemps. On s'est régalés.
Nous avons fait une promenade au parc pour jouer à Pokémon Go ensemble. Ma fille et moi avons coopéré pour battre deux arènes. Nous avons aussi attrapé beaucoup de Pokémon.
Ma fille et moi avons utilisé Claude IA pour générer des cartes mémoire pour apprendre la négation, les conjugaisons du verbe « avoir », et le vocabulaire sur la Saint-Valentin en lisant des phrases humoristiques sur les Pokémon et leurs dresseurs. Nous les avons apprises ensemble. Elle était plus amusée qu'en classe. Je pense que les cartes mémoire de l'IA seront une bonne manière d'apprendre le français si elle n'a pas la possibilité de les faire elle-même.
Comme elle a obtenu de bonnes notes et qu'elle gère bien ses propres responsabilités, je vais renouveler l'abonnement à Claude IA, qu'elle préfère pour générer des histoires interactives.
mardi 17 février
J'avais un rendez-vous avec mon tuteur pendant lequel nous avons commencé à corriger ma prononciation du texte de mon brouillon sur mon apprentissage du français. Les gens conseillent de ne pas s'inquiéter du son «r» mais que je dois travailler mes voyelles et mon rythme. Ça viendra ! Les commentaires de mon tuteur étaient immédiatement utiles. Grâce à sa correction de ma prononciation du mot « psychologique » (où il faut prononcer le « p » initial, qui est muet en anglais), après le rendez-vous, j'ai pu apprendre à ma fille la prononciation du nom « Psykokwak » qui est le Pokémon qui s'appelle Psyduck en anglais. Il était sur une des cartes mémoire hier soir. Après le rendez-vous, j'ai mis à jour mon article et mes enregistrements.
Ma fille m'a dit qu'elle avait atteint un score parfait aux questions sur la négation et les conjugaisons du verbe avoir. Bravo ! L'apprentissage du français nous donne plusieurs occasions de discuter des manières d'apprendre, ce qui est plus utile que des mots spécifiques.
Il faisait beau l'après-midi, donc je me suis assise dehors et j'ai bricolé mon smartphone pour faciliter le basculement entre le dictionnaire et Orgzly Revived en utilisant Tasker pour configurer un raccourci clavier. J'ai finalement trouvé une façon de changer le correcteur automatique de l'anglais au français sur l'application Google Docs. Il fallait utiliser l'interface web pour configurer la langue, car cette option n'est pas dans l'application mobile. L'écran de l'iPad est meilleur que celui de mon smartphone, donc si je peux l'utiliser sur le porche quand il fera beau, je pense que je vais l'apprécier ce printemps.
Après l'école, il y avait de la brume. J'ai essayé de convaincre ma fille de sortir, mais elle a traîné des pieds. Ce n'était pas grave. Je suis allée me promener seule.
mercredi 18 février
J'ai mis à jour la police de caractères qui est créée à partir de mon écriture. Je l'ai créée il y a 6 ans et je l'utilise pour les titres sur mon site pour ajouter une touche personnelle. Maintenant que j'apprends le français, de temps en temps, ces titres sont en français. Jusqu'à présent, les lettres accentuées étaient affichées dans une police de secours. J'ai dépoussiéré mes notes, j'ai dessiné de nouvelles lettres sur mon iPad, je les ai séparées en glyphes que j'ai importés dans FontForge via Python, et j'ai copié des informations sur le crénage d'autres lettres. Le processus a pris un peu de temps parce que la bibliothèque libxml2 était obsolète et j'ai dû la remplacer par lxml. J'ai aussi dû mettre à jour mon logiciel pour convertir les lettres accentuées en noms de glyphes, parce que mon ancien code partait du principe que toutes les lettres étaient simples. J'étais ravie d'avoir réussi. Le résultat a toujours besoin d'être amélioré, mais c'est acceptable pour le moment.
Pour le déjeuner, j'ai préparé des toasts au fromage.
J'ai ajouté une commande vocale pour traduire rapidement du français en anglais quand je dis « okay, translate … ». Elle insère le résultat pour l'instant, mais ce serait peut-être mieux si je l'affichais comme une suggestion de saisie pour me forcer à taper moi-même.
C'est une bonne chose que ma fille ait son propre abonnement à Claude IA au lieu de le partager avec mon mari qui l'essayait aussi. Elle atteint toujours la limite car elle s'en sert pour combattre l'ennui pendant l'école virtuelle. Ce n'est pas un problème pour le moment parce qu'elle gère bien ses responsabilités.
Il faisait un temps de chien, avec la neige et la pluie verglaçante. Nos amis ont annulé leur événement, donc nous sommes volontiers restés à la maison. J'ai déneigé autour de la maison. La neige était très lourde, donc c'était un bon exercice.
Un brouillon pour le Carnaval IndieWeb
Ce mois-ci, le thème du Carnaval IndieWeb est « Intérêts convergents. » C'est peut-être plus facile de lister lesquels de mes centres d'intérêt ne sont pas convergents. Mes centres d'intérêt se recoupent souvent. Je vais commencer par une description de mes premiers intérêts et des façons dont ils sont liés.
La programmation est généralement utile. Je suis particulièrement intéressée par l'automatisation et les aides cognitives et physiques comme l'interface vocale. J'adore Emacs, qui est un éditeur de texte, mais je le bricole à tel point que je l'utilise pour presque tout : gérer mes notes et mes tâches, bien sûr, mais même enregistrer et éditer des fichiers audio et organiser mes dessins.
L'écriture m'aide à penser, à me remémorer et à partager. Org Mode sous Emacs me permet d'utiliser la technique de « programmation lettrée », qui est la combinaison de l'explication et de la programmation. Quelques idées sont plus faciles à penser et à exprimer par le dessin, lequel me permet de les explorer non linéairement. Mes dessins s'appliquent aussi à tous mes centres d'intérêt, comme la parentalité, la technologie, l'apprentissage et la planification. Le sketchnoting est une bonne manière d'apprendre beaucoup de choses, de partager mes notes et de me souvenir de certains moments. Par exemple, ma fille a hâte de finir une synthèse visuelle que nous avons élaborée ensemble, et qui est possible parce que j'avais écrit beaucoup de notes dans le journal web que j'avais développé et dans mon journal en français.
L'apprentissage du français depuis 4 mois touche aussi divers aspects de ma vie quotidienne. J'aide ma fille à l'école, j'essaie d'utiliser l'IA, je bricole mes outils, je regarde des émissions, je cherche des mots pour mes centres d'intérêt. Par exemple, j'ai mis à jour la police de caractères de mon écriture pour inclure les lettres accentuées. Cela a associé le dessin, la programmation, et naturellement l'apprentissage du français. J'ai aussi modifié mon environnement d'écriture sous Emacs pour rechercher les mots dans le dictionnaire et pour afficher les commentaires de l'IA. J'aime particulièrement explorer des techniques d'apprentissage avec ma fille comme les cartes mémoire et les histoires qui suivent le principe de l'apport compréhensible. Quelles méthodes sont efficaces contre quels défis, et comment nous pouvons tirer le meilleur parti des technologies disponibles ? Ce que nous apprenons nous servira bien dans tous les sujets.
De la même manière, l'apprentissage du piano m'aide à apprécier le défi et le plaisir de progresser. Une autre raison de le faire est qu'il aide ma fille à l'apprendre aussi.
Comme ma vie est remplie d'intérêts qui s'entrelacent, c'est important de gérer mon attention face à plusieurs tentations de s'éparpiller, comme la programmation de nouvelles automatisations. Je commence peut-être une tâche et je me retrouve ensuite à faire une tâche complètement différente après une suite d'étapes logiques. On sait ce que c'est, de fil en aiguille. Donc je dois écrire mes notes au fur et à mesure. Rien ne me presse et peu de mes tâches sont urgentes, donc quand je perds le fil de mes pensées, je peux rire et le retrouver. Si j'écris et que je partage ces notes, quelqu'un peut les trouver même après plusieurs années et me les rappeler. C'est très difficile de choisir un moment où j'arrête d'explorer et où je publie mes notes. La tentation est toujours de continuer à suivre une nouvelle idée.
Heureusement, l'effet cumulatif de loisirs qui se complètent m'encourage à grandir, et quand je suis bloquée dans une direction, une ou deux autres pistes se sont ouvertes. En parlant de directions, je trouve que c'est difficile d'écrire quand je veux introduire deux ou plusieurs suites d'idées simultanées, à cause de la linéarité de l'écriture. De toute façon, c'est mieux d'écrire même si c'est un peu décousu.
Je pense que la reconnaissance vocale m'aide à saisir plus d'idées et les progrès technologiques m'aident à les exécuter. Je vais aussi m'améliorer en apprenant et en reliant de nouvelles curiosités à mes autres curiosités. J'ai hâte de voir quelles sortes de choses sont possibles.
Bien que j'aie plusieurs heures de liberté maintenant que ma fille est capable de faire beaucoup de choses elle-même, il y a toujours plus de choses que je veux apprendre. Les loisirs entrelacés se développent, tandis que les loisirs isolés sont oubliés. Par exemple, je ne joue plus à Stardew Valley maintenant que ma fille n'y joue plus. C'est un jeu amusant, mais si je peux choisir un passe-temps, j'en préfère un qui serve des objectifs multiples simultanés. Le jardin de mes intérêts n'est pas formel et ordonné, mais plutôt naturel et entremêlé.
Ma fille a aussi beaucoup de centres d'intérêt. Une année elle s'est intéressée au Cube de Rubik et aux autres casse-têtes, une autre année elle apprenait tout sur Pokémon. Ça ne me dérange pas, tout se combine de façons inattendues. Ce sera intéressant de voir comment elle grandira, et moi aussi.
Merci à Zachary Kai d'accueillir le Carnaval IndieWeb ce mois-ci !
jeudi 19 février
J'ai rangé mes notes pour me préparer à envoyer les titres de mes tâches à l'IA avec mes entrées de journal et mes projets pour qu'elle me suggère d'autres ressources et des idées.
J'ai mis à jour les données pour mon client et j'ai envoyé ma facture.
Après la pause de l'après-midi, j'ai emmené ma fille chez LifeLabs pour un ECG et une prise de sang. Elle était si courageuse. Puis elle a acheté deux bols de nouilles instantanées : aux fruits de mer pour elle et au poulet pour moi. Mon habitude est d'acheter une petite friandise pour ma fille après les rendez-vous médicaux pour lui donner quelque chose qu'elle peut attendre avec impatience pendant un examen médical. Elle préférait le McDonalds, mais maintenant elle préfère les nouilles instantanées.
Pour le dîner, ma fille a préparé des boules de riz au saumon. C'était délicieux.
J'ai essayé la synthèse vocale Kokoro TTS avec un serveur FastAPI. Je la préfère à Google Traduction car elle paraît plus naturelle. Elle me permet de convertir le texte en phonèmes, ce qui est mieux que de convertir mot par mot en utilisant la base de données Lexique parce que Kokoro traite les liaisons. Kokoro génère des horodatages par mot pour l'anglais, mais pas encore pour le français. Ce n'est pas grave, je pense qu'après quelques mois, ce sera possible.
Je me demande quelle est la meilleure façon de tirer profit de mes rendez-vous avec mon tuteur. Je voudrais profiter de son expérience.
- Nous pouvons continuer à corriger ma prononciation avec l'aide des enregistrements.
- Nous pouvons commencer par des sons de base, puis des mots, puis des expressions, puis des phrases.
- Il y a d'autres manières que je ne connais même pas. C'est un long voyage, je n'ai pas besoin de me dépêcher. Je suis heureuse d'essayer des façons variées pour découvrir celles qui sont bonnes pour moi (et peut-être pour ma fille).
vendredi 20 février
Je me suis couchée très tard hier soir. Au réveil, je ne trouvais plus mes lunettes. Heureusement, j'avais des paires de rechange dans un tiroir. Je les ai cherchées. Après une brève recherche, j'ai finalement retrouvé mes lunettes sur mon iPad sur l'étagère.
Pendant le rendez-vous avec mon tuteur, j'ai essayé des virelangues qu'il m'a donnés. Je me suis amusée. Le « r » est trop difficile pour l'instant, mais ça viendra un jour. Nous avons aussi corrigé des mots dans mon journal comme « suggérant » et « apprentissage ». J'ai découvert que mes horodatages n'étaient pas synchronisés avec les fichiers audio, donc j'ai lu mon journal à voix haute.
J'ai ajouté les transcriptions de l'API grâce à Kokoro TTS. Le «r» est toujours très difficile pour moi. Ça viendra un jour. Pour le moment, je vais travailler sur :
- Maman peint un grand lapin blanc.
{mamˈɑ̃ pˈɛ̃ œ̃ ɡʁˈɑ̃ lapˈɛ̃ blˈɑ̃.} - Un enfant intelligent mange lentement.
{œ̃n ɑ̃fˈɑ̃ ɛ̃tɛliʒˈɑ̃ mˈɑ̃ʒ lɑ̃tmˈɑ̃.} - Le roi croit voir trois noix.
{lə ʁwˈa kʁwˈa vwˈaʁ tʁwˈa nwˈa.} - Il est loin mais moins loin que ce coin.
{il ɛ lwˌɛ̃ mɛ mwˈɛ̃ lwˌɛ̃ kə sə kwˈɛ̃.} - Le témoin voit le chemin loin.
{lə temwˈɛ̃ vwˈa lə ʃəmˈɛ̃ lwˈɛ̃.} - Moins de foin au loin ce matin.
{mwˈɛ̃ də fwˈɛ̃ o lwˌɛ̃ sə matˈɛ̃.} - La laine beige sèche près du collège.
{la lˈɛn bˈɛʒ sˈɛʃ pʁɛ dy kɔlˈɛʒ.} - La croquette sèche dans l’assiette.
{la kʁokˈɛt sˈɛʃ dɑ̃ lasjˈɛt.} - Elle mène son frère à l’hôtel.
{ɛl mˈɛn sɔ̃ fʁˈɛʁ a lotˈɛl.} - Le verre vert est très clair.
{lə vˈɛʁ vˈɛʁ ɛ tʁɛ klˈɛʁ.} - Elle aimait manger et rêver.
{ɛl ɛmˈɛ mɑ̃ʒˈe e ʁɛvˈe.} - Le jeu bleu me plaît peu
{lə ʒˈø blˈø mə plˈɛ pˈø} - Ce neveu veut un jeu.
{sə nəvˈø vˈøt œ̃ ʒˈø. - Kokoro TTS utilise « vˈøt œ̃ » pour « veut un », mais Gemini et le tuteur dit que c'est « vˈø œ̃ » sans liaison.} - Le feu bleu est dangereux.
{lə fˈø blˈø ɛ dɑ̃ʒʁˈø.} - Le cœur seul pleure doucement.
{lə kˈœʁ sˈœl plˈœʁ dusmˈɑ̃.} - Le beurre fond dans le cœur chaud.
{lə bˈœʁ fˈɔ̃ dɑ̃ lə kˈœʁ ʃˈo.} - Les fleurs de ma sœur sentent bon.
{le flˈœʁ də ma sˈœʁ sˈɑ̃t bˈɔ̃.} - Tu es sûr du futur ? \\ ** {ty ɛ sˈyːʁ dy fytˈyʁ ?}
- Un mur dur bloque la rue.
{œ̃ mˈyʁ dˈyʁ blˈok la ʁˈy.} - OU / OÙ / OÛ:
- Où sommes-nous, sous ce grand loup ?
{u sˈɔmnˈu, su sə ɡʁˈɑ̃ lˈu ?}
- Où sommes-nous, sous ce grand loup ?
- Le hibou sait où il va.
{lə ibˈu sˈɛ u il vˈa.} - Kokoro TTS utilise « sˈɛt u » pour « sait où », mais le tuteur a dit que « sˈɛ u » sans liaison. - O fermé (devant consonne):
- L’homme fort mord la pomme.
{lˈɔm fˈɔʁ mˈɔʁ la pˈɔm.} - Le sombre col tombe.
{lə sˈɔ̃bʁ kˈɔl tˈɔ̃b.}
- L’homme fort mord la pomme.
- O ouvert / Ô / AU / EAU (fin de syllabe)
- L’auto saute au trottoir chaud.
{lotˈo sˈot o tʁɔtwˈaʁ ʃˈo.} - Le château d’en haut est beau.
{lə ʃatˈo dɑ̃ ˈo ɛ bˈo.} - Raphael says no t; Kokoro included t liaison.
- L’auto saute au trottoir chaud.
Il m'a conseillé de me concentrer sur :
- IN / IM / AIN / EIN / UN vs AN / AM / EN / EM (lapin VS mange)
- EU vs AI / EI / ÈGE / Ê / ETTE (Je VS laine)
- U / Û vs OU / OÙ / OÛ (Tu VS Tout)
Kokoro TTS indique quelques liaisons, mais le tuteur et la synthèse vocale de Google Traduction sont en désaccord avec Kokoro. Je pense que je dois trouver une autre source pour les phonèmes.
Après le rendez-vous, je me suis concentrée sur la différence entre la durée attendue de mon fichier réassemblé et la durée réelle. J'ai modifié ma bibliothèque compile-media pour concaténer des résultats intermédiaires au lieu de traiter en une seule passe. Il y avait encore des bogues.
Il a plu aujourd'hui, donc nous sommes restés chez nous à l'exception de ma brève sortie pour rendre des livres à la bibliothèque.
Ma fille avait mal au dos. Je me demande si elle s'est trop étirée ou si elle avait une mauvaise posture en étant assise sur le canapé.
Nous avons ajouté quelques intérêts et des événements à notre bilan graphique de l'année de ma fille.
La bénévole qui est responsable de l'infolettre cette semaine a une urgence familiale, donc j'ai repris le rôle. C'est facile grâce à mes automatisations.
samedi 21 février
Ma fille a eu du mal à multiplier un nombre à deux chiffres par un nombre à un seul chiffre, peut-être parce qu'elle était occupée à découdre une couture sur sa jupe. Elle est partie en trombe.
Ma fille a reçu de belles fleurs de ses tantes pour son anniversaire. Elle a remarqué que les fleurs LEGO ressemblent beaucoup aux vraies fleurs. Maintenant, notre table a un total de trois vases de fleurs : deux LEGO et un vrai. Elle aime bien les fleurs.
Mon mari et moi avons discuté pour savoir si nous voulions l'ancien four dont son frère s'était débarrassé. D'un côté, cela nécessite de l'argent pour louer un fourgon et demande des efforts pour l'installer, et nous nous étions débrouillés avec seulement notre mini four. D'un autre côté, c'est probablement une bonne occasion pour nouer des liens.
Ma fille et moi avons fait les courses. Nous avons aussi attrapé un Abra Dynamax sur Pokémon Go. Elle a fait tomber un de mes écouteurs Bluetooth et il est tombé dans une flaque, mais heureusement, il fonctionne après avoir séché.
J'ai modifié ma bibliothèque compile-media pour remettre tous les horodatages de paquets audio. Maintenant, la durée du fichier audio final est précise, ce qui permet l'utilisation de MFA pour générer les horodatages par mot.
J'ai commencé à réfléchir à une interface d'analyse de ma prononciation des virelangues. Je veux voir les formes d'onde de l'audio dans un tableau pour faciliter le lancement et la comparaison.
Mon interface de Reddit a commencé à traduire automatiquement toutes les discussions et les commentaires en français. Bien ! Ça transforme mon scrolling en un entraînement à la compréhension.
Ma fille a voulu dessiner un arbre d'intérêts comme l'arbre de lecture que je lui avais fait quand elle apprenait à lire. Elle a fait une petite erreur. J'ai dit que tous les artistes le font, mais elle est devenue trop frustrée et elle est encore partie en trombe. La première fois que j'ai vérifié si elle allait bien, elle était toujours de mauvaise humeur. La deuxième fois, je n'ai fait que des sons du Pokémon Psykokwak. Elle s'est assez amusée à répondre par des sons de Psykokwak. Après un peu plus de détente, elle était prête à demander du ruban correcteur à mon mari. Je pense que le perfectionnisme est un défi pour ma fille.
dimanche 22 février
Ma fille a organisé une réunion virtuelle avec ses tantes et ses cousines. C'était sympa de converser avec elles.
Je me suis dépêchée d'emmener ma fille à son cours de patinage. Nous sommes arrivées un peu tard. Ils ont continué avec l'évaluation des compétences telles que le patinage en arrière. Je pense que ce n'était pas grave, mais j'aimerais vraiment que ma fille trouve un moyen de se préparer à partir plus vite.
Je me suis entraînée aux virelangues en français que mon tuteur m'a donnés. J'ai généré des modèles audio grâce à la synthèse vocale Kokoro, et j'ai ajouté des pauses avec FFmpeg. De cette façon, je peux essayer le virelangue pendant le silence. J'ai enregistré mes tentatives pour les écouter avec mon tuteur mardi, mais je n'en suis pas totalement satisfaite.
- 00:00 Maman peint un grand lapin blanc.
- 00:02 Un enfant intelligent mange lentement.
- 00:05 Le roi croit voir trois noix.
- 00:07 Il est loin mais moins loin que ce coin.
- 00:09 Le témoin voit le chemin loin.
- 00:11 Moins de foin au loin ce matin.
- 00:14 La laine beige sèche près du collège.
- 00:16 La croquette sèche dans l'assiette.
- 00:18 Elle mène son frère à l'hôtel.
- 00:20 Le verre vert est très clair.
- 00:22 Elle aimait manger et rêver.
- 00:24 Le jeu bleu me plaît peu.
- 00:26 Ce neveu veut un jeu.
- 00:27 Le feu bleu est dangereux.
- 00:29 Le beurre fond dans le cœur chaud.
- 00:31 Les fleurs de ma sœur sentent bon.
- 00:33 Un mur dur bloque la rue.
- 00:36 Le hibou sait où il va.
- 00:37 L’homme fort mord la pomme.
- 00:39 Le sombre col tombe.
- 00:40 L’auto saute au trottoir chaud.
- 00:43 Le château d’en haut est beau.
- 00:45 Le cœur seul pleure doucement.
J'ai aussi emmené ma fille chez Sephora pour acheter quelque chose. Elle a choisi un étui pour son désinfectant pour les mains qu'elle peut décorer avec des breloques. Je pense que c'est un peu cher, mais elle peut choisir ce qu'elle veut acheter avec ses propres économies. Elle a voulu m'acheter quelque chose, donc j'ai suggéré des élastiques pour cheveux.
Mon mari a préparé beaucoup de petits gâteaux à l'ananas et à la betterave pour la fête d'anniversaire de ma fille mardi. Parce que notre mini four ne peut cuire que six petits gâteaux à la fois et que la recette utilise du bicarbonate de soude pour faire lever la pâte, car elle réagit une fois qu'il est mélangé, il pense que c'est mieux de diviser les ingrédients en deux lots avant de les mélanger. Il a préparé trois fournées de petits gâteaux et un gâteau.
You can e-mail me at sacha@sachachua.com.
-
🔗 r/LocalLLaMA New Qwen3.5 models spotted on qwen chat rss
 | submitted by /u/AaronFeng47
| submitted by /u/AaronFeng47
[link] [comments]
---|--- -
🔗 r/reverseengineering Writing a game hacking birdfeeder for fun and...fun rss
submitted by /u/suidpit
[link] [comments] -
🔗 r/york Car free walks rss
Hello!
I am wanting to get out of York a bit more and explore the countryside but I don't drive so I would need to use public transport. I've pretty much done every walk you can think of around York so looking for something a bit further further afield but still accessible via bus or train. Bonus points for any good cycling options as well!
submitted by /u/metapaths-25
[link] [comments] -
🔗 r/york I think this is only just over half an hour from York, how cool! rss
 | submitted by /u/Terrible_Passion6178
| submitted by /u/Terrible_Passion6178
[link] [comments]
---|--- -
🔗 r/Harrogate Have any of you seen the christmas show Tinsel Town on TV? rss
submitted by /u/No_Nose_3849
[link] [comments] -
🔗 r/Leeds A huge £15 million entertainment centre with a vast food hall is coming to this northern English city (Leeds) rss
submitted by /u/The_Deacon
[link] [comments] -
🔗 @malcat@infosec.exchange Quick peek at the upcoming 0.9.3 release. It will also feature a 100% headless mastodon
Quick peek at the upcoming 0.9.3 release. It will also feature a 100% headless MCP server for full and pro users.
-
🔗 MetaBrainz Robert Kaye rss
It is with profound sadness that the MetaBrainz Board of Directors announces the unexpected passing of our Founder and Executive Director, Robert Kaye.
Robert’s vision and leadership shaped MetaBrainz and left a lasting mark on the music industry and open source movement. His contributions were significant and his loss is deeply felt across our global community.
The Board is actively overseeing a smooth leadership transition and has measures in place to ensure that MetaBrainz continues to operate without interruption. Further updates will be shared in due course.
-
🔗 r/LocalLLaMA Anthropic's recent distillation blog should make anyone only ever want to use local open-weight models; it's scary and dystopian rss
 | It's quite ironic that they went for the censorship and authoritarian angles here. Full blog: https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks submitted by /u/obvithrowaway34434
| It's quite ironic that they went for the censorship and authoritarian angles here. Full blog: https://www.anthropic.com/news/detecting-and-preventing-distillation-attacks submitted by /u/obvithrowaway34434
[link] [comments]
---|--- -
🔗 r/LocalLLaMA People are getting it wrong; Anthropic doesn't care about the distillation, they just want to counter the narrative about Chinese open-source models catching up with closed-source frontier models rss
 | Why would they care about distillation when they probably have done the same with OpenAI models and the Chinese labs are paying for the tokens? This is just their attempt to explain to investors and the US government that cheap Chinese models will never be as good as their models without distillation or stealing model weights from them. And they need to put more restrictions on China to prevent the technology transfer. submitted by /u/obvithrowaway34434
| Why would they care about distillation when they probably have done the same with OpenAI models and the Chinese labs are paying for the tokens? This is just their attempt to explain to investors and the US government that cheap Chinese models will never be as good as their models without distillation or stealing model weights from them. And they need to put more restrictions on China to prevent the technology transfer. submitted by /u/obvithrowaway34434
[link] [comments]
---|--- -
🔗 r/Leeds Gym feels lonely rss
Hi guys,
I've (22, F) moved to the UK for masters last September. I recently joined a SnapFitness gym to make new friends outside of university. I'm quite a friendly person and don't really have an issue making new friends; however, going to the gym here feels so lonely cause everyone has earphones in all the time. No one talks to anyone. Are gyms not an avenue to make friends? Is it a thing that in UK gyms, people just come to work out and run back home? I'm wondering if this is some kind of culture shock or something for me.
submitted by /u/Pemberley_21
[link] [comments] -
🔗 r/Harrogate Knaresborough Tractor Run 2026 — Who’s Going? 🚜 rss
submitted by /u/No_Nose_3849
[link] [comments] -
🔗 r/Harrogate New Knaresborough Subreddit – Come Join Your Local Community! rss
Hi everyone! I’ve recently taken over r/knaresborough, which had been inactive and unmoderated for years. My goal is to revive it as a friendly, town-focused subreddit for residents and visitors to share photos, local news, events, and hidden gems.
It’s a space for Knaresborough locals to connect, celebrate the town, and have an alternative to Facebook 😄.
Come check it out and join the conversation!
submitted by /u/No_Nose_3849
[link] [comments]
-
![[link]](https://i.redd.it/hinq4mb883mg1.jpeg){kind=link}
![[link]](https://i.redd.it/wesoexqo73mg1.jpeg){kind=link}
![[link]](https://i.redd.it/u2171tcfu2mg1.jpeg){kind=link}
![[link]](https://i.redd.it/wy3k1f6z42mg1.png){kind=link}
![[link]](https://i.redd.it/929gfwhz93lg1.jpeg){kind=link}
{kind=link}
![[link]](https://i.redd.it/t97gnmjai0mg1.jpeg){kind=link}
![[link]](https://i.redd.it/0e1gvioz1wlg1.jpeg){kind=link}
![[link]](https://i.redd.it/jcgeuvshpvlg1.jpeg){kind=link}
![[link]](https://i.redd.it/zy274dnepvlg1.jpeg){kind=link}
![[link]](https://i.redd.it/qieyviy9pvlg1.jpeg){kind=link}
{kind=link}
{kind=link}
![[link]](https://i.redd.it/nut97509culg1.jpeg){kind=link}
![[link]](https://i.redd.it/522vbj37tslg1.jpeg){kind=link}
![[link]](https://i.redd.it/f624mg43aslg1.jpeg){kind=link}
![[link]](https://i.redd.it/moxh9n8r4slg1.jpeg){kind=link}
![[link]](https://i.redd.it/5g4ostqlbnlg1.png){kind=link}
![[link]](https://i.redd.it/01z55js38nlg1.png){kind=link}
{kind=link}
![[link]](https://i.redd.it/f9x0emmuillg1.png){kind=link}
{kind=link}
![[link]](https://i.redd.it/h1c3uk0iwflg1.png){kind=link}
![[link]](https://i.redd.it/1ulaheylwclg1.png){kind=link}