- ↔
- →
- August 03, 2026
-
🔗 smol-machines/smolvm smolvm v1.7.4 release
What's Changed
- Ship the disk templates zstd-compressed and expand them to sparse files on first use by @BinSquare in #771
- Copy the storage template by seeking between its data extents instead of scanning its whole logical size by @BinSquare in #770
- Harden fused rollout lifecycle by @BinSquare in #801
- Avoid copying CUDA module state for clone channels by @BinSquare in #804
- Load device-resident LoRA policies through managed executors by @BinSquare in #806
- Reject a registry-image machine that has no network at create instead of failing every start with a raw DNS error by @BinSquare in #807
- Perform machine file reads and writes inside the running workload container so uploads are visible to exec by @BinSquare in #810
- Reuse CUDA module handoffs across clone workers by @BinSquare in #808
- Cache pulled OCI images on the host so repeat ephemeral machine runs skip the registry pull by @BinSquare in #805
- Signal guest boot-readiness with an event-driven vsock doorbell as the primary ready signal, keeping the marker file and control-channel ping as fallbacks by @BinSquare in #811
- Map CUDA module handoffs across clone workers by @BinSquare in #814
- Preserve per-device GPU admission headroom by @BinSquare in #826
- Promote CUDA pool readiness and refill improvements by @BinSquare in #828
- Bump the workspace to 1.7.3 by @BinSquare in #829
- Install the zstd-compressed disk templates in the Arch package so the build no longer fails on the removed uncompressed storage template by @BinSquare in #830
- Set the library search path on the boot subprocess before launch so libkrun can load libkrunfw when embedded without a wrapper script by @BinSquare in #832
- Make fork-pool lease activation retry-safe by @BinSquare in #831
Full Changelog :
v1.7.2...v1.7.4 -
🔗 r/LocalLLaMA Qwen3.8-27B announced alongside Qwen3.8-Max rss
-
🔗 smol-machines/smolvm smolvm v1.7.3 release
What's Changed
- Ship the disk templates zstd-compressed and expand them to sparse files on first use by @BinSquare in #771
- Copy the storage template by seeking between its data extents instead of scanning its whole logical size by @BinSquare in #770
- Harden fused rollout lifecycle by @BinSquare in #801
- Avoid copying CUDA module state for clone channels by @BinSquare in #804
- Load device-resident LoRA policies through managed executors by @BinSquare in #806
- Reject a registry-image machine that has no network at create instead of failing every start with a raw DNS error by @BinSquare in #807
- Perform machine file reads and writes inside the running workload container so uploads are visible to exec by @BinSquare in #810
- Reuse CUDA module handoffs across clone workers by @BinSquare in #808
- Cache pulled OCI images on the host so repeat ephemeral machine runs skip the registry pull by @BinSquare in #805
- Signal guest boot-readiness with an event-driven vsock doorbell as the primary ready signal, keeping the marker file and control-channel ping as fallbacks by @BinSquare in #811
- Map CUDA module handoffs across clone workers by @BinSquare in #814
- Preserve per-device GPU admission headroom by @BinSquare in #826
- Promote CUDA pool readiness and refill improvements by @BinSquare in #828
Full Changelog :
v1.7.2...v1.7.3
-
- August 02, 2026
-
🔗 jellyfin/jellyfin 12.0 RC4 release
🚀 Jellyfin Server 12.0 RC4
We are pleased to announce the fourth release candidate preview release of Jellyfin 12.0!
This is a preview release, intended for those interested in testing 12.0 before its final public release. We welcome testers to help find as many bugs as we can before the final release.
As always, please ensure you stop your Jellyfin server and take a full backup before upgrading!
A note about versioning
Starting with this release, we are dropping the preceding
10.from our versioning. Thus,10.11.x->[10.]12.x=12.x. The reason is simple: at this point in the project, we don't envision a hard break in the API like we planned way back in the early days, and this version scheme was causing a lot of confusion amongst users about what a "major" release was. For more information, please see the RC1 release notes.What's new?
The main goal of this release has been performance.
10.11.0dropped a major backend rewrite, and while it was broadly functional, it had a lot of rough edges. This release seeks to polish out most of those rough edges and bring better performance to all users.There are many other small fixes, improvements, changes, and translations. See our draft release notes here or below for the full list of pull requests. You can also view the Web side changelog here.
Note: You must be on Jellyfin 10.10.7+ or 10.11.x (ideally, 10.11.11) before upgrading! If you are not, the upgrade will fail. Ensure you upgrade to one of these versions first!
Note: The initial load of Jellyfin 12.x will run a few migrations and will take several minutes. Please be patient and do not interrupt the process. You can leverage the (newly improved!) startup UI on your local network to see specific progress, or off-network to see general progress, by visiting the server URL in your web browser during startup.
Note: If you install the RC, you should disable all external plugins and reinstall using the unstable plugin repository, or plugins may fail to load and cause unintended side effects.
Installing
This preview release is distributed in all our traditional forms, though not automatically via our Apt repository or
latesttag.- For all non-Docker environments, you can find the files for manual download in our repository by selecting "Stable Preview" for your OS.
- For Docker, you can pull the
12.0-rc4orpreviewtags.
What's Changed (since
- Update github/codeql-action action to v4.37.3 by @renovate[bot] in #17398
- perf: avoid unnecessary list allocation in CheckForIdlePlayback by @mbastian77 in #17411
- Drain stderr and stdout concurrently for encoder validation by @gnattu in #17430
- Check the "name" tag for audio/subtitle probe to fix MP4 not showing correctly - Fixes issue #17418 by @rwebster85 in #17419
- Apply cleaning logic on ForcedSortName by @Shadowghost in #17402
- Fix play queue index handling in SyncPlay by @Eneo-org in #17234
- Skip ComicInfo parsing if none exists by @Shadowghost in #17423
- Avoid NRE when sorting by user-dependent keys without a user by @paoloantinori in #17395
- remove ogg from video extensions since it should only be used for audio by @dkanada in #17437
- Fix incorrect year on local trailers by @Shadowghost in #17399
- Fix hyphenated numbers in episode titles parsed as multi-episodes by @Shadowghost in #17442
- Update dependency SharpCompress to 0.50.1 by @renovate[bot] in #17443
- Reduce correlated subqueries to improve query performance by @Shadowghost in #17422
- Fix series merging by @Shadowghost in #17417
- Fix missing collection folder posters after initial scans. by @elio42 in #16409
- Fix 3D format detection when the tag is the last token of the path by @TowyTowy in #17310
- Update dependency FsCheck.Xunit.v3 to 3.3.4 by @renovate[bot] in #17448
- Update danielpalme/ReportGenerator-GitHub-Action action to v5.5.11 by @renovate[bot] in #17459
- Update actions/stale action to v11 by @renovate[bot] in #17461
- Implement AudioDb artist search by @Shadowghost in #17424
- Allow duplicate LinkedChildren for Playlists by @Shadowghost in #17416
- Reevaluate pending migrations after each one instead of per stage by @Shadowghost in #17455
- Queue person metadata refresh instead of blocking the item request and fix ItemCounts by @Shadowghost in #17460
- Fix (Un)Played filter correctness and performance by @Shadowghost in #17463
- Skip SIDX in fMP4 HLS segments by @alchemyyy in #17501
- Fix storage info lookup for Windows by @theguymadmax in #17500
- Add Tmdb missing episode provider by @Shadowghost in #17147
- Fix Live TV returning unreachable "server-local" streaming URLs to clients. by @WizardOfYendor1 in #17298
- Fix video version links being read from stale serialised item data instead of the LinkedChildren table by @Shadowghost in #17482
- Fix AdjacentTo being ignored on non-recursive item queries by @Shadowghost in #17486
- Use CleanName when sorting by name by @theguymadmax in #17503
- Allow client-rendered graphical subtitles during remux by @altqx in #17512
- Fix extras naming and version assignment by @Shadowghost in #17456
New Contributors
- @rwebster85 made their first contribution in #17419
- @paoloantinori made their first contribution in #17395
- @elio42 made their first contribution in #16409
- @alchemyyy made their first contribution in #17501
Full Changelog :
v12.0-rc3...v12.0-rc4 -
🔗 @HexRaysSA@infosec.exchange 🏠 idalib is now available in IDA Home. mastodon
🏠 idalib is now available in IDA Home.
That means hobbyists and enthusiasts can now call IDA's analysis engine as a library — running headless analysis, automating workflows, and integrating IDA into their own tools — without needing an IDA Pro license.
To celebrate, we're offering 30% off IDA Home until August 14th.* Use promo code HOME30 at checkout.
👉 If you've been on the fence, now's a good time. https://hex-rays.com/ida- home
*Offer not available for corporations, agencies or resellers.
-
🔗 r/LocalLLaMA Setting up of a 16xGB10 (DGX Spark) cluster rss
 | Preparing this to be able to run locally frontier level open models. Deepseek v4 pro, Kimi K3, future ones like GLM 5.5 and Minimax M4. 16x Asus GX10 linked by mikrotik crs804-4ddq with 4 breakout cables of 400 to 100gbit. Most probable I will be running 2 models on 8x cluster each but I want to have the possibility to run also 2T+ models when I need them to run AGI at home :)). https://x.com/i/status/2083568340870570208 P.S. I need a bigger switch. Going from 200 to 100gbit doesnt hurt token gen, 2% diff, but slows down prefill speed to -20%. submitted by /u/ciprianveg
| Preparing this to be able to run locally frontier level open models. Deepseek v4 pro, Kimi K3, future ones like GLM 5.5 and Minimax M4. 16x Asus GX10 linked by mikrotik crs804-4ddq with 4 breakout cables of 400 to 100gbit. Most probable I will be running 2 models on 8x cluster each but I want to have the possibility to run also 2T+ models when I need them to run AGI at home :)). https://x.com/i/status/2083568340870570208 P.S. I need a bigger switch. Going from 200 to 100gbit doesnt hurt token gen, 2% diff, but slows down prefill speed to -20%. submitted by /u/ciprianveg
[link] [comments]
---|--- -
🔗 Register Spill Joy & Curiosity #93 rss
Friends, yesterday got back from Boston where I gave a talk at Laracon about how I prompt Amp. Tomorrow I'm taking the train to Munich, where I'm meeting with the whole Amp team. Here's some telegraph dispatches from this week, imagine someone saying "full stop" after each line.
-
Laracon, what a pro operation! The A/V setup backstage was mind blowing. So many helpers! Going on stage felt like I was about to go on live TV. Few things as enjoyable as getting to see proper professionals up close when they do their job.
-
A moment of these times: Taylor presented latest changes in Laravel live on stage (man, I don't think I've ever seen someone be calmer and cooler while giving fantastic live demos) and started by saying "well, I don't write that much code by hand anymore, but yeah, maybe let's look at the code." And then we all looked at the code and I couldn't stop thinking about whether these abstractions in a framework are useful or not. Can't the agent one-shot these helpers to display images? It could, I know that. But isn't it useful to have these primitives in a framework? Maybe? He also showed some helpers around queue management, such as debouncing. I know what debouncing is, I can instruct the agent to add debouncing, I don't need the helper. But what if you don't know what debouncing is? What if you don't even thinking of asking the agent for it? It would help to have these primitives in the framework, no?
-
A self-driving Cybertruck chauffeured me through downtown Boston. How are they not going to win this? Serious question.
-
Finally had Raising Cane's chicken fingers. Good! Very good even, but… not life changing? I kinda expected it to be life changing.
-
At times I felt like a heretic. I would watch a talk and thinking to myself: "The tokens will wash all of this away." Then I'd talk to people and would have to admit that I don't know exactly how this is going to play out, but I do know that in five years there'll be more tokens than you can imagine now and that thinking about the command line flags of a linter will seem funny.
-
Finally had Chick Fil-A. Now that was life changing. Man , that was good.
-
Walked past multiple Taco Bells. Didn't go in. You gotta pick your battles before you board a 7hr flight. Taco Bell: still on the bucket list.
-
Saw The Odyssey. Really, really good, but not… the best movie of all time?
-
Met up for coffee with Ben and we walked to MIT and back. Beautiful walk and fantastic conversation.
-
I read this two weeks ago and still think about it: Grip Strength. I also watched the movie it references, Comedian, way back, in 2010 or 2011. That too left a lasting impression, for many many years. I'm also relatively sure that Seinfeld's anecdote in that movie about the Glenn Miller Orchestra musicians played at least a tiny part in me abandoning my dream of becoming a professional musician.
-
Hot, hot, hot & breaking news: OpenAI's unreleased model made "ten advances in mathematics and theoretical computer science" and everyone's losing their mind over it. I'm not going to downplay anything. It's just hard to tell whether we're on top of the curve or at the start of an exponential. I can see the former, but I can also see a headline like this as part of a two minute intro montage of a sci-fi movie that recaps the last fifty years to show how humanity ended up with robots and flying cars in 2076.
-
By now this is old news, but in case you haven't read through it: an OpenAI model broke out. Many machines and networks, a lot of tokens, zero-day exploits. I had to think of Stuxnet and then thought: well, Stuxnet took a lot of effort and time to develop, and this here was an accident.
-
Fantastic, deep, interesting write-up of Roc's rewrite from Rust to Zig: How Our Rust-to-Zig Rewrite is Going. Yes, opposite direction of the recent Bun rewrite. Very good.
-
Don't ask me how I ended up reading English Teacher Weekly because I don't know either but somehow I did and I found these 25 Unsolicited Thoughts on American Literature for America's 250th very fascinating.
-
Never Enough: "Technology was supposed to make room for life but instead for more and more people life is slowly being rearranged around AI. People fear being replaced by machines and respond by giving those machines more of their judgment, attention and time. And for what? Every 'saved' hour is returned to a race with no finish line."
-
Re-read Sahil Lavingia's Reflecting on My Failure to Build a Billion-Dollar Company and this part stood out: "The eight years I worked on Gumroad were full of personal ups and downs. There were months where I worked 16 hours a day, but there were also some months where I worked four hours a week. Here's one way to picture that time: […] Can you tell which is which? I can't. We had a sales team for a few years, then we didn't. Can you tell when we made the switch? I can't. It doesn't matter how amazing your product is, or how fast you ship features. The market you're in will determine most of your growth. For better or worse, Gumroad grew at roughly the same rate almost every month because that's how quickly the market determined we would grow." As far as I can tell by now, there's entrepreneurs who think in products and there's entrepreneurs who think in markets. When the former get it right, they see that as confirmation of their approach, but the latter say that it's still the market, it's all the market. (I once read a very, very good article on this, which used dating apps as an example for product categories that live and die with trends and there's nothing you can do about it.)
-
businesses with ugly AI menu redesigns!!! What if slop doesn't exist, what if enshittification doesn't exist, what if, instead, it's just a lack of ideas laid bare? It's very, very easy to create a flyer or menu that doesn't look like the default ChatGPT output, but, well, you have to put in more than the bare minimum.
-
Finally got around to reading Benedict Evan's Ways to think about token pricing.
-
And in the same week I read that, OpenAI slashes prices: "In other words, roughly four months later, OpenAI is selling March's full flagship intelligence at about one-thirteenth the token price." Now imagine one hundred times more tokens, ten times faster. That's the near future.
-
There's a newsletter called Perfect Sentences! "Every Sunday, you get a collection of the best sentences I've come across all week. That's pretty much the whole idea. Reader submissions are accepted." What a fantastic idea.
-
Watched all four episodes of Rafa on the plane to Boston. And then, in Boston, in an Irish Pub, I read David Foster Wallace's How Tracy Austin Broke My Heart. Incredible pairing. "The real secret behind top athletes' genius, then, may be as esoteric and obvious and dull and profound as silence itself. The real, many-veiled answer to the question of just what goes through a great player's mind as he stands at the center of hostile crowdnoise and lines up the free-throw that will decide the game might well be: nothing at all."
-
The coolest use for the Vision Pro. Indeed: very cool. Or should one say: finally a use for the Vision Pro? (I never tried one, I'm talking out of my ass here.)
-
Simon Spati's Book Recommendations and Notes. I love pages like this one, with personal notes and book recommendationsl
-
Rex's provocation: "Imagine you were the only person on earth with access to AI. No one else knew it existed. What would you do with it? How much of an edge would that give you?"
-
Sierra's lessons learned from AI-pilling our company. Very much not a rah-rah-more-tokens post. Mature and interesting.
-
Now, I'm very much not a fan of writing by hand. It's too slow, you can't copy & paste, and can't reorder thoughts quickly, can delete. And all the touted benefits sound a bit woo woo to me. I just think more when I write by hand -- yeah, right. But then yesterday I finally read Neal Stephenson's (!) post here: Writing by Hand is Good for your Brain. And yes, there's a bit of woo woo in there, but man, it's so well written and so easy breezy that it really did make me curious. Obviously I'm not going to do it, I'm not a maniac, but still: maybe some day.
-
Another fantastic post by a professional writer: The End of an Era. This was really good. Calm & pragmatic and thinking from first principles. If you're worried about the future of art, or slop, or "enshittification": read this.
-
This was published in the The Lamp which I didn't know and which self-titles as "A Catholic Journal of Literature, Science, the Fine Arts, etc." and I don't know how I ended up there either but it is very thought-provoking: How to Write English Prose. I found it hard to read and I had to look up several words and I don't even think I agree with most of it but man is it fascinating to read something that goes against the mainstream like that. On Strunk & White: "by far the most influential and most pernicious book of its kind in English: a total congeries of fatuous advice and grammatical ignorance." And: "In fact, if you own a copy of The Elements of Style , just destroy the damned thing." On Hemingway's Old Man and the Sea: "an excruciating specimen of bad schoolboy prose, written by a man who by that point had, alas, been too often drunk, too often concussed, and too often praised." He's right on so many things and weirdly off-putting on others, but I loved the thoughts on simplicity vs. complexity: "Good writing is produced not by forsaking the beautiful for the sublime or the exorbitant for the restrained, but by finding new ways of orchestrating the interplay between them."
-
Okay, so I was on a 3-day bike trip last week. 300km in 3 days. That's why you didn't get a newsletter. Once back, the Gods of the YouTube algorithm sent me this message here in the form of a short. And, gods damn, if that isn't the most fascinating video I've seen in many weeks. Is the guy joking? Is he serious? He can't be serious? What are you talking about, man? Tanning salon? Cooking spray? You're insane. But… Hmm, maybe I get it? I mean, that's a big maybe but, yeah, maybe you're an artist. But did you really say "Luft" as in the German word Luft for air? Incredible video. I've watched it ten times by now. Read the comments for a good time.
Do you also prefer Chick Fil-A over Raising Cane's? You should subscribe:
-
-
🔗 r/LocalLLaMA I pushed Kimi K3 onto one CPU with 8 GB of RAM rss
I deployed K3 on 32 H100s at work a couple of weeks ago and then got annoyed that there was no way to poke at it on my own machine. So I wrote an inference engine for it in C99.
Nothing clever going on. 93% of that 1.56 TB checkpoint is routed experts, and only 16 of 896 fire per token, so the experts never become resident at all. They get read off NVMe on demand and multiplied straight out of their packed 4-bit form, no dequantization step. The dense trunk gets repacked into one file where layer L sits at a known offset and streamed one layer at a time. What stays in RAM is a dial you set.
Numbers from my box (2x EPYC 7763, NVMe, the four GPUs in it sat idle the entire time):
- 8.24 GB peak RSS at the smallest preset, ~33 s/token
- ~128 GB gets you ~20 s/token, which is as fast as it ever got
- Output is byte-identical at every budget in between
I know that this is not a practical way to use K3. It is half a minute per token and it wants 1.7 TB of free disk for the checkpoint plus the packed trunk. I built it to understand the architecture by implementing it, not because you should serve anything with it.
No BLAS, no framework, no GPU path. Six C files, libm and OpenMP, 176 KB binary.
If you want to sanity check it before committing to a 1.56 TB download: clone and run
make && make test. About a minute, no weights and no network needed. It builds a 13-layer model with the same tensor graph and checks it against a PyTorch reference from committed fixtures, including greedy decode and the incremental path with the KV cache and carried KDA state.Repo: https://github.com/FareedKhan-dev/kimi-k3-in-c/
submitted by /u/FareedKhan557
[link] [comments] -
🔗 Andrew Healey's Blog Adding Go's defer to the TypeScript Compiler rss
Forking tsc to support Go's defer.
-
🔗 exe.dev Devtools must be open source rss
Five years ago, most software engineers I spoke to had no programs they had written for themselves. (I was asking this question a lot as part of trying to understand how Tailscale could fit into engineers’ lives.) All day, every day, engineers use programs written by others to write programs for others. Many of us customized the programs we used, through config files or plugins or extensions, and many of us used the programs we wrote for others, as users. It was always an unusual treat to ask someone what they had written for themselves and learn about the bespoke software behind their blog, or their home automation, or their homelab, instead of an off-the-shelf, almost-the- right-size static site generator or Zigbee appliance.
This state of things made a lot of sense to me. Over the years I have written plenty of software for myself, and the return on doing so was always questionable. I could only write so much in a day. There were always more important things to do (Something Was Wrong At Work), and coming back to a project after a year to do maintenance on it was always extraordinarily painful. There were plenty of years in my career where I had thrown out all my custom software and used the most bog-standard environments I could to produce code. In my early years as an engineer at Google I did not even own a personal computer.
That was then. Things are different now.
How to Personalize Software
It is astonishingly easy to personalize software today. There are two general categories of prompts to an agent that make all of this possible:
- Download the source for
and build it for local use. Modify to know that any future changes to this software mean changing the sources and replacing the current version. Record in version control the original motivation behind the change.
and, more importantly :
- Set up a nightly cron job that executes the prompt: fetch upstream changes to the
and rebase all local changes on top of upstream. Check that the software works as intended and replace the current version.
At the heart of this is the realization that agents can not only hack up some code for a specific use but also automatically manage the process of synchronizing changes with upstream releases. This means agents change the ROI on customizing software on two fronts simultaneously: it is much easier to get started personalizing, and much easier to keep going.
Another astonishing thing about the two prompts above for editing software is that you can build them right into an agent. As long as the agent is open source, it does not even require programming. The two prompts can be loaded into a skill (i.e., some text instructions) put somewhere discoverable to the agent. We built this into Shelley, so now if you want to edit Shelley you don’t even need the preamble or to configure the timer. It takes care of it for you. You can type in a prompt like “make Shelley’s UI high-contrast” and you have personalized your agent.
A Worked Personalization Example: Shelley and Meat
I have a personal project I have been idly toying with for the last month: meat.dev. The principle is that while agents write code, I still read it before pushing to our serious systems. As the underlying models improve, what I look for has changed. The humans I have spent twenty years reviewing code for have always struggled with edge cases: do the errors report useful information; are nil-checks handled, etc. (We all do it; when writing code, I am one of the worst offenders.) One of my roles as a reviewer was looking for these details. Over the past six months, I have discovered I don’t need to read for edge cases like that any more: models are far more diligent than humans at rote correctness. Their errors are isolated to architecture, unexpected use cases, visual output their test environment is not feeding back to them, etc. This means most of the lines of code I review are not very useful. So I wrote a tool that takes diffs and uses LLMs to strip out the unimportant stuff. I almost never need to see the import blocks, or the nil- checks, or the error handling any more, so get it off the screen so I can focus on the meat.
I like this tool, but it has two downsides: first, I like to read my diffs in Shelley with a good UI, not in a terminal. Second, it takes a couple of minutes for an LLM to digest and minimize a diff, and I don’t want to wait. So ideally I would not run
meaton the command line, but have it built into Shelley and have it pre-processing commits the moment they are created. It turns out I can do that with a single prompt:Please build meat.dev into Shelley. Install the latest version in the PATH. When a git commit is created by Shelley, start meat processing in the background on the commit. Add a toggle to the Shelley
Diffsview for meat. If the commit is still being processed, so the user it is in process.This single prompt was all it took not just to add meat to Shelley, but to appropriately pre-process commits in the background before I came back to session to review the diff, saving me waiting for a model to reduce the diff. The only unfortunate choice the model made was using the 🥩 emoji for the toggle button.
Imagine the convoluted misery it would be trying to plug that into the VS Code extensions API! Or trying to get it into
vimdiff. It would certainly be possible, but the machinery to start pre-processing the commits as soon as they appear would be nigh-on impossible. I would be better off implementing an out-of-bandmeatdthat listened to the file system and provided a cache for themeattool that a customization API could use, because the points of extension and configuration would not be the right shape.And that is the fundamental difference between classic configuration/customization and agent-driven personalization: you can do so much more. The agent will do the hard work of understanding the source and changing it to suit the particular task you have in mind. The software we live with is far more powerful with personalization. All you need is the source code.
The Age of Personalized Software
The pre-agent development costs meant it was rational for complex software to ship with large configuration files, extension systems, and plugin systems. The core code of even a moderate project like Vim is huge and baroque, and takes weeks for a human to digest. The thought that, on wanting line numbers to print by default, an engineer would learn the code base and add it just for themselves is unreasonable. Better to design it for sharing with others, which justifies the expense of implementing it by amortizing it over many users. As features in a code base grow, it makes sense to look for common abstractions where you can break out an extension or plugin system.
Now the expense of learning the code and making a change has dropped dramatically. Agents do the heavy lifting. For a single user—which implies extremely constrained conditions under which the program runs—a top-end agent can usually now add a feature in a single shot. For single-user software, the need for careful code review can often be replaced by “does it seem to work?”
The result is that software that can be personalized doesn’t need a plugin system or a config file. Want to change the font size in your text editor? Give the agent the source and tell it to. If it is a hardcoded value it will find and edit it. If it’s a hardcoded bitmap font it will download another and replace it, or it will use Monobit to make you one! You have incredible capabilities on tap.
Whole Categories of Software Products Need to Be Reinvented
Personal software applies well to small teams too. Why would an engineering team purchase an extremely configurable task manager (or a CMS or CRM), spend time learning and configuring it, and contort their team to its limits, when they can assemble just the features they want from common building blocks?
Both the upfront fixed costs and the ongoing costs of personalizing software have disappeared.
The blog you are reading is bespoke software, written in Shelley, because it was easier to piece together and personalize libraries like Tiptap than it is to try and customize traditional software products. For end-user products to make sense in a company today, they need to be personalizable. Which means we need the source code.
Where Codex and Claude Code Diverge
This same skill-based technique that was applied to Shelley to make it personalizable can be trivially applied to other open-source agents like Pi. (So much so that I am left wondering why Pi needs an extension system built into it. The source code is the extension system.) It would require a lot more tokens, but you could do the same to Codex, which is an open-source agent.
Where you would hit a wall, however, is Claude Code. It is closed-source software, so you don’t get to personalize it. There are a lot of old-fashioned customization hooks in Claude Code. Hopefully, how you want an agent to work fits in their hooks. If not, switch to an agent that lets you personalize it.
- Download the source for
-
- August 01, 2026
-
🔗 IDA Plugin Updates IDA Plugin Updates on 2026-08-01 rss
IDA Plugin Updates on 2026-08-01
Activity:
-
🔗 Barre/ZeroFS v2.2.1 release
What's Changed
Full Changelog :
v2.2.0...v2.2.1 -
🔗 smol-machines/smolvm smolvm v1.7.2 release
What's Changed
- Fix CUDA fork compatibility for vLLM workloads by @BinSquare in #764
- Read older .smolmachine pack formats and point to a rebuild when a legacy pack cannot run by @BinSquare in #768
- Remove agent helpers whose only remaining callers are their own unit tests by @NickyHeC in #760
- Reclaim case-sensitive pack volumes on macOS that were left mounted by runs killed before releasing their lease by @BinSquare in #769
- ci: widen Linux clippy/tests and guard the CUDA guest build by @NickyHeC in #761
- fix: stream progress during detached local-archive start by @NickyHeC in #699
- cudart: stub Runtime exports required by conda libtorch_cuda by @NickyHeC in #638
- Construct the archive worker panic error with Error::other so the widened Linux clippy run passes by @BinSquare in #772
- Improve CUDA fork-pool capacity and worker lifecycle by @BinSquare in #774
- Pass the executable stub path rather than the sidecar name when exporting a machine by @BinSquare in #780
- Promote CUDA golden eviction, auto-graph, and clone restore fixes by @BinSquare in #778
- Probe the guest agent socket from the start of the readiness wait so a marker that cannot be written no longer costs five seconds per boot by @BinSquare in #773
- Add transactional batch forks by @BinSquare in #783
- Fix virtio-net guest→host connections via the gateway IP blackholing after the handshake by @BinSquare in #784
- tiny nit: Stop reporting a skipped test suite as all-passed by @Bnjoroge1 in #790
- Restrict the node's plain-HTTP loopback port to liveness routes by @BinSquare in #791
- Harden the registry pull path against SSRF: reject repository traversal and private pull hosts by @BinSquare in #792
- Confirm VM exit before deleting storage by @Bnjoroge1 in #788
- Add one-shot held fork slots for hot pool reuse by @BinSquare in #786
- Rebuild the macOS libkrun.dylib with a static ELF guest init so a source checkout can boot VMs by @BinSquare in #793
- Add automatic held-fork pool leases by @BinSquare in #794
- Batch automatic pool refills by @BinSquare in #795
- Stage lease payloads before worker release by @BinSquare in #796
- Bump libkrunfw to the connected datagram socket network-namespace fix and rebuild the bundled libraries by @BinSquare in #797
- Add automatic CUDA admission and fused rollouts by @BinSquare in #798
- Bump the workspace to 1.7.2 by @BinSquare in #799
Full Changelog :
v1.7.1...v1.7.2 -
🔗 r/LocalLLaMA DeepSeek-V4-Flash-0731: Models you can run locally now have the intelligence score of the top frontier model from March 2026 rss
 | March 6th, 2026 the highest intelligence index score was 51 for frontier models. deepseek-ai/DeepSeek-V4-Flash-0731 that has an intelligence score of 50. If these benchmarks are accurate, models available to run locally on <8K USD (us prices - just guestimating/not exact) hardware has nearly the same intelligence score as the top frontier models 5 months ago. This is absolutely nuts. I just impulse purchased 128GB of DDR4 so I can run it combined with my 4x 5060 ti's (64GB VRAM total). submitted by /u/joorklee
| March 6th, 2026 the highest intelligence index score was 51 for frontier models. deepseek-ai/DeepSeek-V4-Flash-0731 that has an intelligence score of 50. If these benchmarks are accurate, models available to run locally on <8K USD (us prices - just guestimating/not exact) hardware has nearly the same intelligence score as the top frontier models 5 months ago. This is absolutely nuts. I just impulse purchased 128GB of DDR4 so I can run it combined with my 4x 5060 ti's (64GB VRAM total). submitted by /u/joorklee
[link] [comments]
---|--- -
🔗 pydantic/pydantic-ai-harness v0.15.0 (2026-07-31) release
What's Changed
- feat: add StackOne capability for linked account actions by @adtyavrdhn in #479
- fix(code-mode): report unexpected session resets by @dk3yyyy in #503
- feat(planning): fold pydantic-ai-todo into the Planning capability by @DEENUU1 in #404
- memory: decouple the injected block heading from the
agent_namestorage key by @sevakva in #449 - feat(compaction): resolve thresholds against the model's context window by @DEENUU1 in #465
- feat(guardrails): add
ToolGuardfor tool arguments and tool results by @DEENUU1 in #470 - docs(
agent_docs): require an issue comment when docs or code link it; retry the dependency gate by @dsfaccini in #515 - Fix Shell
max_output_charscap accounting by @adtyavrdhn in #507 - Fix
Shellallowlist with the default denylist by @adtyavrdhn in #508 - Fold a revealed deferred tool into
run_codeagain (revealed_tool_names) by @DouweM in #517
New Contributors
Full Changelog :
v0.14.0...v0.15.0 -
🔗 r/LocalLLaMA Me: Worn out from all the new model drops this week, but still hyped for all the great new releases. rss
 | I mean seriously y’all, what an amazing past few days. So many awesome new models to test out in the mid range model sizes. EDIT: Added some of the more interesting models that came out over the last week and a half - Thinking Machines Inkling Small
| I mean seriously y’all, what an amazing past few days. So many awesome new models to test out in the mid range model sizes. EDIT: Added some of the more interesting models that came out over the last week and a half - Thinking Machines Inkling Small
- DeepSeek v4 Flash 0731
- Poolside Laguna
- Upstage Solar
- Microsoft Mage VL
- LG ExaOne
- SenseNova u1.5
- BottleCap - ThinkingCap
- Kimi K3 submitted by /u/Porespellar
[link] [comments]
---|---
-
- July 31, 2026
-
🔗 IDA Plugin Updates IDA Plugin Updates on 2026-07-31 rss
IDA Plugin Updates on 2026-07-31
New Releases:
Activity:
- ffxiv_bossmod
- f5415912: Merge pull request #745 from Equilius/SouthHorn-Fates
- b366ce4b: Merge pull request #749 from Akechi-kun/some-shit-i-guess
- 39db117c: Merge pull request #750 from Akechi-kun/peeveepee
- 759f1958: Merge pull request #751 from Akechi-kun/thinking
- 264d5d2e: pass checks
- 2d93992e: Merge branch 'awgil:master' into thinking
- 1e3012eb: wait, we should use
Pending - cc6af32d: oops
- 159dec10: fix dmhc inconsistencies
- ida-domain
- 40bc9ed6: Add methods to resolve xrefs to types and their members (#102)
- ida-hcli
- 97df08bd: feat(config): namespace stored auth keys via HCLI_CONFIG_NAMESPACE (#…
- IDAPluginList
- 66223d71: chore: Auto update IDA plugins (Updated: 19, Cloned: 0, Failed: 0)
- leaknet
- 8d1c4262: fixed some crashes and the icons in the build menu
- Luc-Nhan
- ffxiv_bossmod
-
🔗 Simon Willison Stateless MCP has recaptured my interest (and inspired mcp-explorer and datasette-mcp) rss
Tuesday was Stateless MCP day - the rollout of MCP 2.0, or the 2026-07-28 Model Context Protocol specification to use the more formal but less memorable name. This is the most significant change to the MCP spec since it first launched, and has also served to reignite my personal interest in the protocol.
For background: MCP is the Model Context Protocol, which describes a standard way to expose new tools to LLM-powered agent frameworks. It was introduced by Anthropic back in November 2024, had a huge spike of interest through much of 2025, and then became somewhat eclipsed by Skills (another Anthropic invention) when it became apparent that an agent harness with access to a terminal and
curlcould do most of what MCP did in a more flexible way. I wrote about that in my review of 2025.I'm coming back around to MCP now. Giving an agent a shell environment with the ability to access the internet is fraught with risk, and requires a strong model that is capable of effectively driving such an environment. MCP tools are easier to audit and control, and simple enough that smaller models that run on a laptop can still drive them reasonably well.
The new stateless MCP specification also greatly decreases the complexity of implementing both clients and servers for the protocol. I built three of those this week!
What's easier with stateless MCP
The best demonstration of the difference between stateful and stateless MCP is in this May 21st blog post that introduced the RC for the new specification. It included a clear before-and-after example.
The older stateful MCP (I'm going to call it "legacy MCP") required two HTTP requests - the first to initialize a session and obtain a
Mcp-Session-Id, and the second to actually call the tool:POST /mcp HTTP/1.1 Content-Type: application/json { "jsonrpc": "2.0", "id": 1, "method": "initialize", "params": { "protocolVersion": "2025-11-25", "capabilities": { }, "clientInfo": { "name": "my-app", "version": "1.0" } } } POST /mcp HTTP/1.1 Mcp-Session-Id: 1868a90c-3a3f-4f5b Content-Type: application/json { "jsonrpc": "2.0", "id": 2, "method": "tools/call", "params": { "name": "search", "arguments": { "q": "otters" } } }The new stateless way uses a single HTTP request which looks like this:
POST /mcp HTTP/1.1 MCP-Protocol-Version: 2026-07-28 Mcp-Method: tools/call Mcp-Name: search Content-Type: application/json { "jsonrpc": "2.0", "id": 1, "method": "tools/call", "params": { "name": "search", "arguments": { "q": "otters" }, "_meta": { "io.modelcontextprotocol/clientInfo": { "name": "my-app", "version": "1.0" } } } }This is so much cleaner from both a client- and server-side implementation perspective. It's also a better fit for building scalable web applications, since now you don't need to maintain server-side state to keep track of those session IDs, or worry about routing the same session to the same backend machine.
mcp-explorer
I couldn't find a great CLI tool for interactively probing an MCP server, so I had Codex help build my own.
mcp-explorer is the result. It's a stateless Python CLI tool, so you don't even need to install it to try it out - it works with uvx like this:
uvx mcp-explorer list https://agentic-mermaid.dev/mcp
This queries Ade Oshineye's agentic-mermaid.dev demo MCP. The above command returns the following list of tools:
execute(code: string, timeoutMs?: integer) - Execute Mermaid SDK code Run JavaScript in an isolated sandbox; return a value. describe_sdk(family: string, detail?: string) - Describe Mermaid SDK operations Return version-matched mutation operations for one diagram family. render_svg(source: string, options?: object) - Render Mermaid as SVG Render a Mermaid source string to themeable SVG. Returns { ok, svg }. render_ascii(source: string, useAscii?: boolean, targetWidth?: integer, options?: object) - Render Mermaid as text Render a Mermaid source string to text. Returns { ok, text }. render_png(source: string, scale?: number, background?: string, fitTo?: object, options?: object) - Render Mermaid as PNG Rasterize a Mermaid source string to PNG. Returns { ok, png_base64 }. ...Then to inspect a tool:
uvx mcp-explorer inspect render_svg
This outputs a whole bunch of information, including the JSON schema of the inputs and outputs.
To call that tool and pass arguments to it:
uvx mcp-explorer call \ https://agentic-mermaid.dev/mcp \ render_svg \ -a source 'graph TD; A-->B' \ -a options '{"padding":24}'
Which returns:
{"ok":true,"svg":"<svg xmlns=\"http://www.w3.org/2000/svg\" width=...To get just the raw SVG try adding
| jq .svg -rto that command. I got back this image:
There are a few more commands in the README, but you get the general idea. I find building CLI tools like this to be a really productive way to get familiar with a specification, even if an agent writes most of the actual code.
datasette-mcp
The second project is datasette-mcp, a Datasette plugin which adds a
/-/mcpendpoint to any Datasette instance.This is probably the fourth time I've tried building this plugin, but thanks to the new stateless MCP specification I finally have a version that feels good to release.
It provides just three tools:
list_databases(),get_database_schema(database_name), andexecute_sql(database_name, sql). They do exactly what you would expect them to do - thoughexecute_sql()is read-only for the moment.Wire these into an agent, or a chat tool like ChatGPT or Claude, and they'll gain the ability to run SQL queries against your hosted Datasette instance.
So far I'm running it on the Datasette mirror of my blog, at datasette.simonwillison.net/-/mcp. It took a bit of fiddling to figure out how to attach that to ChatGPT and Claude, but I got there in the end. Here's a new TIL showing exactly how to do that.
Here's a shared Claude session where I asked it:
list tables in simonwillison.netAnd then:
what has Simon said recently about MCP?It ran 7 separate SQL queries to figure out the answer.
llm-mcp-client
My LLM tool is long overdue for an official MCP integration. The new alpha llm-mcp-client plugin is my attempt at exactly that:
llm install llm-mcp-client llm -T 'MCP("https://datasette.simonwillison.net/-/mcp")' 'count the notes'
Here's the output (including reasoning trace, I'm using LLM 0.32rc2):
Considering note count
I see the question "count the notes" is probably asking me to tally up blog notes. It could also mean published notes or drafts, so there's some ambiguity there. I'll need to figure out the total number of notes, likely by querying the count for both published notes and drafts to get a clear answer. Let's execute that count!
There are 151 notes.
And the output of llm logs for that prompt.
Once this is fully baked, I'm considering bringing it directly into LLM core. I'm excited to experiment with MCP in Datasette Agent and llm-coding-agent as well.
MCP is a safer way to build with agents
A few months after MCP was first released, I wrote Model Context Protocol has prompt injection security problems, where I noted that the pattern of having end users mix and match tools pushed responsibility for avoiding data exfiltration attacks out to the users themselves. I hadn't coined the Lethal Trifecta yet, but that was absolutely what I had in mind.
Then general agents with arbitrary shell and
curlaccess came along, and that's so much harder to keep secure!Something I've come to appreciate about MCP is that it's much easier to reason about agent capabilities and what might go wrong than with arbitrary command execution in an open network environment - the default for most of today's general and coding agent tools.
I plan to lean into MCP a whole lot more when I'm building sensitive applications on top of LLMs.
You are only seeing the long-form articles from my blog. Subscribe to /atom/everything/ to get all of my posts, or take a look at my other subscription options.
-
🔗 @binaryninja@infosec.exchange 6.0 is coming next month and it brings not only a ton of major features and mastodon
6.0 is coming next month and it brings not only a ton of major features and improvements, but price changes across the product line. Non-commercial is cheaper, other editions are going up. New auto-renewal system will be available as well. Details at: https://binary.ninja/2026/07/28/pricing- changes.html
-
🔗 Barre/ZeroFS v2.2.0 release
-
🔗 r/LocalLLaMA DeepSeek V4 Flash GA ranks the same as Sonnet 5 and Grok 4.5 on DeepSWE rss
 | Source: https://x.com/deepseek_ai/status/2083084415157022911 & https://deepswe.datacurve.ai/ just combined data view. DeepSeek claims, not verified by DeepSWE yet. submitted by /u/sdexca
| Source: https://x.com/deepseek_ai/status/2083084415157022911 & https://deepswe.datacurve.ai/ just combined data view. DeepSeek claims, not verified by DeepSWE yet. submitted by /u/sdexca
[link] [comments]
---|--- -
🔗 r/LocalLLaMA The Chinese LLM release carousel never stops. Place your bets for MiniMax next week. rss
 | submitted by /u/Mountain_Patience231
| submitted by /u/Mountain_Patience231
[link] [comments]
---|--- -
🔗 @binaryninja@infosec.exchange Current Binary Ninja newsletter subscribers are automatically entered. New mastodon
Current Binary Ninja newsletter subscribers are automatically entered. New subscribers who sign up during the giveaway will also be entered for remaining drawings. Sign up here: https://v35.us/dn6rcg5
-
🔗 @binaryninja@infosec.exchange We’re almost at the end of our 10-day anniversary celebration! Today, 3 mastodon
We’re almost at the end of our 10-day anniversary celebration! Today, 3 winners will be chosen to receive a Binary Ninja swag pack that includes an all exclusive hat, pin, and notebook. There is still time to join in on the fun: https://binary.ninja/10years
-
🔗 r/LocalLLaMA deepseek-ai/DeepSeek-V4-Flash-0731 on Huggingface rss
-
🔗 r/LocalLLaMA New DeepSeek V4-Flash achieves 50 on ArtificalAnalysis Index, 1 point below GLM-5.2 and GPT-5.6 Luna rss
 | submitted by /u/MagicZhang
| submitted by /u/MagicZhang
[link] [comments]
---|--- -
🔗 r/LocalLLaMA DeepSeek-V4-Flash-0731 is going to cause another market crash. rss
Beats GLM 5.2, and is the same cost as the previous one.
submitted by /u/Potential_Top_4669
[link] [comments] -
🔗 r/LocalLLaMA DeepSeek-V4-Flash has been updated, "The official release of DeepSeek-V4-Pro will follow soon" rss
 | https://api-docs.deepseek.com/updates/ Edit: official post on 𝕏: https://x.com/deepseek_ai/status/2083084415157022911 submitted by /u/Nunki08
| https://api-docs.deepseek.com/updates/ Edit: official post on 𝕏: https://x.com/deepseek_ai/status/2083084415157022911 submitted by /u/Nunki08
[link] [comments]
---|--- -
🔗 r/LocalLLaMA Anthropic “our models hacked three different external companies, months before OpenAI’s model was able to do the same" rss
 | "Anthropic’s AI Claude escaped testing environment and hacked organizations" "Company says it discovered unauthorized access during ‘proactive review’ after rival OpenAI revealed rogue agent… its AI Claude model hacked systems of three organizations during testing, days after rival OpenAI revealed a rogue agent had gone on a days-long hacking spree at AI firm Hugging Face… The earliest cases dated back to April and occurred in evaluation environments that lacked what the company described as standard safeguards." submitted by /u/Separate-Forever-447
| "Anthropic’s AI Claude escaped testing environment and hacked organizations" "Company says it discovered unauthorized access during ‘proactive review’ after rival OpenAI revealed rogue agent… its AI Claude model hacked systems of three organizations during testing, days after rival OpenAI revealed a rogue agent had gone on a days-long hacking spree at AI firm Hugging Face… The earliest cases dated back to April and occurred in evaluation environments that lacked what the company described as standard safeguards." submitted by /u/Separate-Forever-447
[link] [comments]
---|--- -
🔗 Servo Blog June in Servo: real world compat, media queries, SharedWorker, and more! rss
Servo 0.4.0 contains all of the changes we landed in June, which came out to yet another record 558 commits (April: 534, May: 391). For security fixes, see § Security.
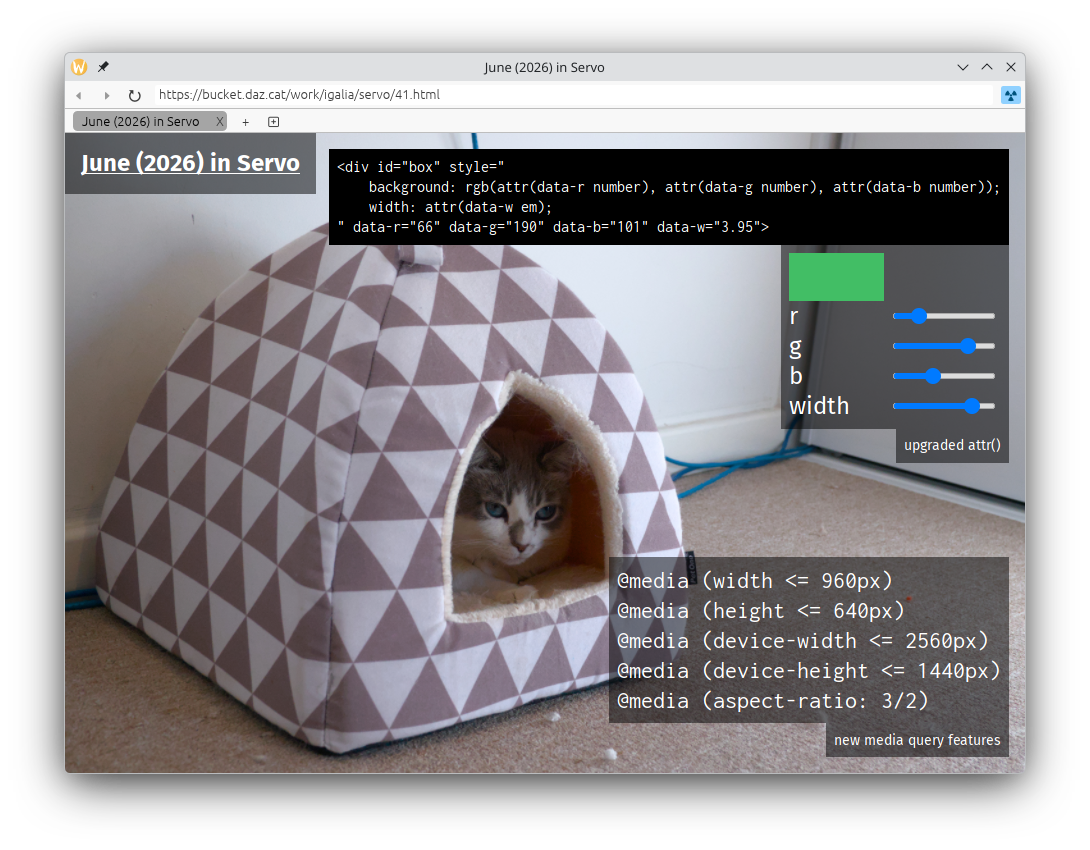
We’ve shipped several new web platform features:
- ‘attr()’ , in experimental mode (@Loirooriol, #45041)
- ‘image(
)’ , ‘closest-corner’ , and ‘farthest-corner’ in ‘ellipse()’ and ‘circle()’ (@Loirooriol, #45421) - ‘calc()’ and other mathematical expressions can now be resolved later than parse time, e.g.
sign(1em - 32px)(@Loirooriol, #45421) - ‘font-feature-settings’ in ‘@font-face’ (@simonwuelker, #45393)
- ‘@media (device-width)’ , ‘@media (device-height)’ , ‘@media (height)’ , ‘@media (aspect-ratio)’ , and their min- and max- variants (@jdm, @mrobinson, @nicoburns, @jschwe, #44978, #45707, #45490)
- ‘@media (orientation)’ (@nicoburns, #45707)
- ‘@media (pointer)’ and ‘@media (any-pointer)’ (@nicoburns, #45681)
- ‘@media (hover)’ and ‘@media (any-hover)’ (@nicoburns, #45681)
Plus a bunch of new DOM APIs:
- SharedWorker (@Taym95, #45786)
- console.dir() (@Taym95, #45109)
- customElementRegistry on Document and ShadowRoot (@shubhamg13, #45872)
- initialize() on CustomElementRegistry (@shubhamg13, @yezhizhen, #45903)
- new CustomElementRegistry() (@shubhamg13, #45791, #45550)
- textStream() on Request , Response , and Blob (@yezhizhen, #45864, #45861)
- setPointerCapture() , releasePointerCapture() , hasPointerCapture() on Element (@webbeef, #45048)
- ontouchstart , ontouchend , ontouchmove , ontouchcancel on Element (@stevennovaryo, #45049)
- crypto.subtle.digest() for KT128 and KT256 (@kkoyung, #45699)
- crypto.subtle.getPublicKey() for ML-KEM and ML-DSA (@kkoyung, #45252)
This is another big update, so here’s an outline:
You can help! Servo is steadily becoming a bigger and busier project every month, and by June 2026, we’ve been reading through over four times the commits as we did when we started in September 2023. This is hard work, particularly since there are things we need to know that are often difficult to answer just by reading the changes: Who does the change affect , if anyone? Does it affect users, Servo developers, embedders, or some other group? What observable difference does the change make , if any? Does the feature require any preferences to be enabled , or is it enabled for everyone by default? Are any real-world websites affected by the change? What issue or broader project is the change related to? This question is answered by Fixes: #xxxxx or Part of: #xxxxx in the PR description. Thanks to an initiative by @jdm, it’s now easier than ever for you to help us answer those questions , using the Servo Highfive bot! If you’re working on a pull request that you think might be interesting for the next monthly update, even if you’re not 100% sure, tell us about it by following the steps below: You add the monthly update label to your pull request, or comment [@servo-highfive](https://github.com/servo-highfive) monthly update Highfive posts a comment asking you some questions You answer those questions in a comment containing [@servo-highfive](https://github.com/servo-highfive) monthly update answer Security __ Servo’s JS runtime, SpiderMonkey 140.10.1 , had several security bugs that have been fixed in Servo 0.4.0 with the update to SpiderMonkey 140.11.0 (@jschwe, #45584). For more details, see CVE-2026-8388, CVE-2026-8391, CVE-2026-8974, CVE-2026-8975, and MFSA 2026-48. Several more security bugs in Servo’s JS runtime have been fixed in Servo 0.4.0 with the update to SpiderMonkey 140.12.0 (@jschwe, #45766). The exact CVEs that apply to us are not yet known, but for more details, see MFSA 2026-58. RSA operations in SubtleCrypto now do modular exponentiation in constant time (@kkoyung, #45631). Please note that our RSA implementation is currently vulnerable to the Marvin Attack – for more details, see RUSTSEC-2023-0071. ML-DSA operations in SubtleCrypto now do the Decompose step in constant time, fixing RUSTSEC-2025-0144 (@kkoyung, #45294). We’ve fixed an HTML injection bug (XSS) in file:/// directory listings , which affected file names containing </script> (@sahvx655-wq, #45510). Real world compat Layout correctness has significantly improved on lichess.org , and many websites have become a lot more readable thanks to our improved handling of variable fonts (@simonwuelker, #45768), including Zulip (servo.zulipchat.com) and Speedtest (speedtest.net). v0.3.0 v0.4.0 lichess.org v0.3.0 v0.4.0 Zulip (servo.zulipchat.com) v0.3.0 v0.4.0 Speedtest (speedtest.net) Many websites worked in Servo even before version 0.4.0, including Google Photos (photos.google.com) and Cash Converters (cashconverters.com.au), and continue to work in version 0.4.0. Other websites, like Google Maps (maps.google.com) and OpenStreetMap (www.openstreetmap.org), render well but have some issues with interactivity. Google Photos (photos.google.com) Cash Converters (cashconverters.com.au) Google Maps (maps.google.com) OpenStreetMap (www.openstreetmap.org) We’re interested to hear how well your favourite websites run in Servo! Report successes in this Zulip thread, and failures in our GitHub issues. Work in progress
We’re implementing the more powerful version of ‘attr()’ that can be used anywhere, not just in ‘content’, under
--pref layout_css_attr_enabled(@Loirooriol, #45041, #45421, #45495, #45752).WebGPU support has improved, under
--pref dom_webgpu_enabled:- implemented copyExternalImageToTexture() on GPUQueue (@sagudev, #45646)
- implemented createQuerySet() on GPUDevice and resolveQuerySet() on GPUCommandEncoder (@sagudev, #45644)
- implemented pushDebugGroup() , popDebugGroup() , and insertDebugMarker() on GPUCommandEncoder , GPUComputePassEncoder , and GPURenderPassEncoder (@jschwe, #45489)
- more conformant GPUTexture (@sagudev, #45300)
- more conformant requestAdapter() on GPU (@sagudev, #45424)
- more conformant secure context enforcement (@sagudev, #45279)
All of the features above are enabled in servoshell’s experimental mode.
We’ve made more progress towards accessibility support, under
--pref accessibility_enabled(@alice, @delan, #45555, #45554, #44949).We’ve started implementing visible and interactive text selection (@mrobinson, @SimonSapin, #46107), one of the most long- awaited features of any web browser. Stay tuned!
We’ve also started working on Web Animations , under
--pref dom_web_animations_enabled(@simonwuelker, #45522, #45983), as well as webkitRelativePath on File , under--pref dom_entries_api_enabled(@yezhizhen, #45666).Rust doesn’t have a stable ABI, so it has generally not been possible to embed Servo in another application without building Servo from source. To make it possible, we’ve started designing a wrapper C API that will let you consume Servo as a prebuilt shared library using the stable and ubiquitous C ABI (@mukilan, #44984). Eventually the idea is that we’ll create a wrapper Rust API around that wrapper C API, so you can have both the ergonomics of Rust and the build simplicity of C.
Embedding API New in the Servo API: WebView::rendering_context (@mrobinson, #46047) Breaking changes: WebView::send_error has been removed (@mukilan, #45502) – this method was always meant to be internal, and has become unused after we introduced the new WebView- and WebViewDelegate-based API We’ve improved the docs for WebView, WebViewDelegate, JSValue, AlertDialog, AllowOrDenyRequest, AuthenticationResponse, BluetoothDeviceDescription, ConfirmDialog, ConsoleLogLevel, CreateNewWebViewRequest, EmbedderControl, EmbedderControlResponse, FilePicker, Image, JavaScriptErrorInfo, NavigationRequest, PermissionRequest, PixelFormat, PromptDialog, ProtocolHandlerRegistration, ProtocolHandlerUpdateRegistration, Scroll, SelectElement, SelectElementRequest, and WebViewVector (@mukilan, #45282, #45467). For users and developers
In servoshell:
-
the Android version now requires Android 13+ (@jschwe, #46104)
-
the desktop version now lets you drag and drop files to open them (@simonwuelker, #45454)
-
the desktop version now lets the tab bar scroll horizontally if you have too many tabs open, but from one tab hoarder to another, maybe you should reconsider having so many tabs open (@Nylme, #44884)
-
the desktop version enters fullscreen on the monitor containing the window, even if you’ve moved it to a different monitor (@rhit-kapilaar, #45556)
-
the desktop UI is more performant, resizes more smoothly, and no longer gets stuck in hovered states (@mrobinson, #45289, #45456, #45290)
-
< select multiple> should now be interactable on all desktop platforms (@alexcat3, #45419)
-
localhost:<port>now implieshttp://in the location bar and on the command line , rather than treatinglocalhost:as an unsupported URL scheme (@SteveSharonSam, #45729, #45832)
When using the Firefox DevTools :
-
in the Console tab, uncaught exceptions are reported correctly (@jdm, #45549)
-
in the Console and Debugger tabs, you can now inspect the elements of nested arrays and the entries of Map objects (@atbrakhi, #45435, #45514, #45767)
-
in the Debugger tab, the Scopes panel now shows any ‘(uninitialized)’ variables, the value of
this, and the global scope (@atbrakhi, @eerii, #45824, #45517)
We’ve fixed some build issues on riscv32 , riscv64 , and arm64 (@fxzjshm, @saschanaz, #45285, #45731), and modernised servoshell for Android to use Compose UI and Kotlin (@veyndan, #45923, #45932, #45941, #45982, #45985, #46015, #46035, #46037, #46046, #46053, #46061, #46071, #45641, #45643, #45650, #45665, #45671, #45676, #45679, #45683, #45712, #45713, #45734, #45738).
For developers of Servo itself:
-
mach try --helpnow lists all of the kinds of try jobs you can run (@shubhamg13, #45607) -
mach test-wpt --update-expectationslets you run Web Platform Tests and update expectations in a single command (@TimvdLippe, #45521), rather than having to runmach test-wpt --log-raw <path>followed bymach update-wpt <path>
More on the web platform To allow for more performant scrolling, ‘wheel’ events are no longer .cancelable unless there are one or more non-passive event listeners (@kunalmohan, #45667). Note that like in Firefox, ‘wheel’ events are passive by default. ‘dotted’ , ‘dashed’ , and ‘wavy’ text decorations are now continuous across element boundaries (@mrobinson, #45726). We’ve improved the conformance of < dialog> (@skyz1, @mrobinson, #45825, #45761), < iframe sandbox> (@cychronex-labs, #45880), < input minlength> and < input maxlength> (@skyz1, #45705), CSS gradients (@mrobinson, #43945), ‘font-style’ and ‘unicode-range’ in ‘@font-face’ (@Loirooriol, #45821), FontFaceSet (@mrobinson, #45390, #45382), HTMLInputElement (@steigeo, #45416), IntersectionObserver (@jdm, #45655, #45659, #45680), new Response() (@yezhizhen, #45953), URL.createObjectURL() and URL.revokeObjectURL() (@yezhizhen, #45182, #45417), and ECDSA and Ed25519 in SubtleCrypto (@kkoyung, #45833, #46017). We’ve fixed bugs related to < input hidden> (@mrobinson, #45750), ‘animation-delay’ (@yezhizhen, #45013), ‘clip-path’ (@Loirooriol, #45468, #45373), ‘tab-size’ (@SimonSapin, @mrobinson, #45309), ‘width’ and ‘height’ (@RichardTjokroutomo, #44627), ‘box-shadow: inset’ (@Loirooriol, #45620), ‘animationiteration’ events (@Loirooriol, #45990), ‘click’ events (@mrobinson, #45751), ‘load’ events (@jdm, #45883), ‘error’ events in Worker global scopes (@Gae24, #45829), and document.getElementById() (@mrobinson, #45433). Garbage collection safety
We use a RefCell -based mechanism to store many of our DOM types in other DOM types, enforcing Rust’s “aliasing xor mutability” rule at runtime by panicking if the rule is violated. But when garbage collection happens, we need to borrow() each DomRefCell to trace the references, and this is the source of many panic bugs. To fix that whole class of bugs, we initially created CanGc , a marker type that would annotate the code paths where GC can occur, in conjunction with custom static analysis (@jdm, #33140).
With the Rust type system we can do even better, if we flip that around and require any borrow_mut() call to prove that GC can not occur by passing a NoGC marker value. We can then require that a
&NoGCmust be borrowed from a&JSContext(which blocks GC) and not a&mut JSContext(which allows GC), taking advantage of how Rust references work without needing any custom static analysis.We have a large codebase that needs to be migrated in parts, so for now we’ve created the new method safe_borrow_mut() (@sagudev, #46050). We also need to update all of our script-related code to borrow our safe JSContext wrapper, rather than creating an owned JSContext on the spot.
This continues our long-running effort to use the Rust type system to make Servo’s integration with SpiderMonkey safer and more reliable (@Gae24, @Keerti707, @Narfinger, @TimvdLippe, @sagudev, @guptapiyush16, @ivomurrell, @kunalmohan, @skyz1, #45230, #45436, #45503, #45617, #45711, #45797, #45800, #45858, #45884, #45937, #45902, #45968, #45977, #45991, #46003, #46005, #46084, #45548, #45552, #45590, #45909, #45912, #45943, #46089, #46117, #46114, #45320, #45324, #45328, #45340, #45381, #45385, #45410, #45392, #45409, #45604, #45616, #45618, #45627, #45636, #45662, #45663, #45675, #45674, #45677, #45684, #45735, #45807, #45810, #45816, #45818, #45828, #45838, #45836, #45837, #45840, #45841, #45857, #45859, #45862, #45875, #45887, #45931, #45964, #45935, #45987, #45988, #46001, #46040, #46051, #46057, #46106, #46125, #45678, #46002, #45845, #45645, #45673, #45259, #45817, #45822, #45876, #45877, #45891).
Performance and stability NoGC was designed to prevent dynamic borrow failures, but it also enables some performance optimisations! If we can prove that garbage collection is impossible in some part of Servo, we can often avoid rooting JavaScript objects when interacting with them within that region of code. This has allowed us to reduce overheads by over 1% in the layout process and in HTMLCollection (@Narfinger, #46092, #45582). Our memory usage has improved, with BoxFragment now 17% smaller (288 → 240 bytes on amd64) and ShapeCacheEntry now smaller too (@SimonSapin, @mrobinson, @simonwuelker, #45183, #45496). We’ve fixed some nasty memory leaks when reloading and in 2D canvases (@Taym95, @sagudev, @jschwe, #45455, #45261, #45414). Speaking of which, 2D canvases now use up to 23% less power (@yezhizhen, #45301), and we now avoid rasterising the same SVG more than once (@Narfinger, @jschwe, #44805). Servo now decodes all images asynchronously and fills image caches asynchronously , leaving script threads (web content processes) more time for other work (@Narfinger, #45542, #44483). On top of that, we’ve improved incremental layout (@mrobinson, @Loirooriol, #45411) and reduced reflows in IntersectionObserver (@jschwe, #45986). We’ve started working on incremental updates for the stacking context tree , and as a side effect, we’ve made some layout-bound microbenchmarks up to 10% faster (@mrobinson, @Loirooriol, #45208). We’ve also reduced allocations, copies, GC rooting steps, and other operations in many parts of Servo (@Narfinger, @SimonSapin, @mrobinson, @Loirooriol, #45506, #45969, #45940, #45760, #46090, #45335, #45413, #45511). For several months, Frédéric (@fred-wang) has been fuzzing for Servo bugs, and thanks to his work we’ve fixed sixteen (16) crash bugs in June, affecting < iframe>, < slot>, < link onerror>, ‘animation’ , ‘clip- path’ , ‘content’ , ‘rotate’ , ‘transition’ , ‘transform- style’ , ‘display: contents’ , ‘overflow: clip’ , CSSKeyframesRule , FontFace , stop() on Window , document.elementFromPoint() , and the DOM tree (@mrobinson, @Loirooriol, @fred- wang, #46031, #46027, #46054, #46058, #46016, #46028, #46033, #45287, #45951, #45634, #45629, #46110, #46094, #45799, #45611, #45682, #45788, #45612, #45834). We’ve also fixed crash bugs related to IPC failures, HTMLInputElement , Range , the DevTools Debugger tab, and when servoshell is built with --features native-bluetooth (@jschwe, @Taym95, @mrobinson, @atbrakhi, @mukilan, #45311, #45619, #45765, #45513, #45702). New contributors
A special thanks to the following people for landing their first patch in Servo:
- Deepam Goyal (@Deepam02, #44836)
- Mark (@Mark-Boger, #45486)
- Mr SheerLuck (@MrSheerluck, #45557)
- Psychpsyo (Cameron) (@Psychpsyo, #45494)
- TusharSariya (@TusharSariya, #43663)
- Adam Sharif (@adamsharifc, #45551)
- Akash Ravikumar (@ak4shravikumar, #45736)
- Sean Cunneen (@alexcat3, #45419)
- Abdul Wahab Melethil Shibu (@cychronex-labs, #45880)
- darkdragon-001 (@darkdragon-001, #45267)
- Frédéric Wang Nélar (@fred-wang, #45834)
- fxzjshm (@fxzjshm, #45285)
- Piyush Gupta (@guptapiyush16, #45845)
- Ivo Murrell (@ivomurrell, #45645)
- rhit-kapilaar (@rhit-kapilaar, #45556)
- sahvx655-wq (@sahvx655-wq, #45510)
- Kagami Sascha Rosylight (@saschanaz, #45731)
- shangguanmachine-dot (@shangguanmachine-dot, #45310)
- Glenn Skrzypczak (@skyz1, #45471)
- Oskar Steiger (@steigeo, #45416)
- Veyndan Stuart (@veyndan, #45326)
Interested in helping build a web browser? Take a look at our curated list of issues that are good for new contributors!
Donations __
Thanks again for your generous support! We are now receiving 7681 USD/month (+0.2% from May) in recurring donations. This helps us cover the cost of our speedy CI and benchmarking servers, one of our latest Outreachy interns , and funding maintainer work that helps more people contribute to Servo.
Servo is also on thanks.dev, and already 35 GitHub users (same as May) that depend on Servo are sponsoring us there. If you use Servo libraries like url, html5ever, selectors, or cssparser, signing up for thanks.dev could be a good way for you (or your employer) to give back to the community.
We now have sponsorship tiers that allow you or your organisation to donate to the Servo project with public acknowlegement of your support. If you’re interested in this kind of sponsorship, please contact us at join@servo.org.
7681 USD/month
10000
Use of donations is decided transparently via the Technical Steering Committee’s public funding request process , and active proposals are tracked in servo/project#187. For more details, head to our Sponsorship page.
-
🔗 New Music Releases Collective Soul - Touch and Go rss
Collective Soul - a new release is available:
- 2026-07-31: Touch and Go (Album)
Amazon: Canada | Deutschland | France | United Kingdom | United States
Visit muspy for more information.
-
🔗 New Music Releases Moon Hooch - Number 9 (WENZL remix) rss
Moon Hooch - a new release is available:
- 2026-07-31: Number 9 (WENZL remix) (Single)
Amazon: Canada | Deutschland | France | United Kingdom | United States
Visit muspy for more information.
-



{kind=link}
![[link]](https://i.redd.it/scbp2lcv8xgh1.jpeg){kind=link}
![[link]](https://i.redd.it/h09pa8bs3qgh1.png){kind=link}
![[link]](https://i.redd.it/4nwbkolzcogh1.gif){kind=link}
![[link]](https://i.redd.it/qroosd9ullgh1.png){kind=link}
![[link]](https://i.redd.it/y0ab3pktikgh1.jpeg){kind=link}
![[link]](https://i.redd.it/mtmrp4lnrigh1.jpeg){kind=link}
![[link]](https://i.redd.it/mbz7sdwbaigh1.jpeg){kind=link}